Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent: The Ultimate Optimizer
Paper and Code
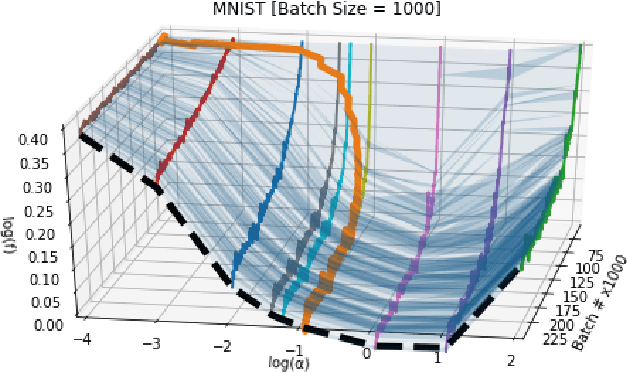
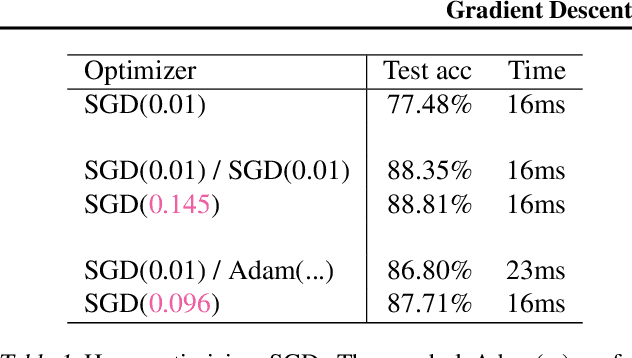
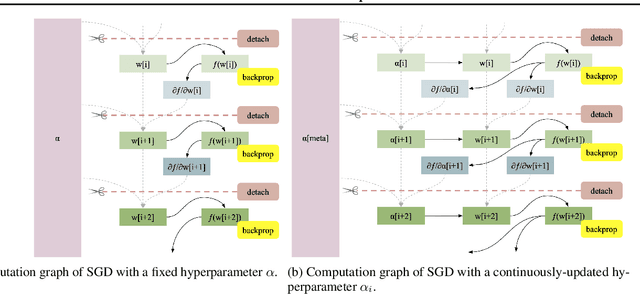
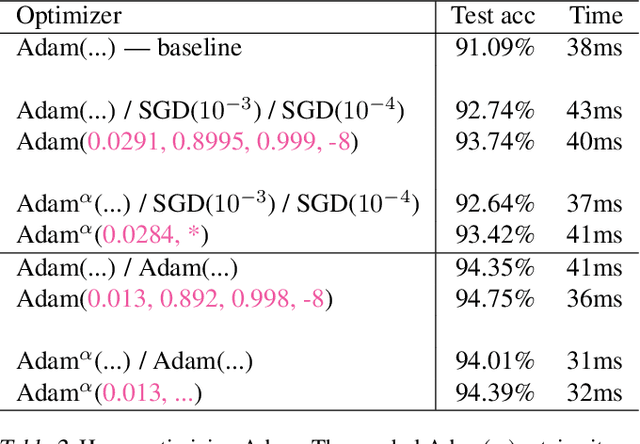
Working with any gradient-based machine learning algorithm involves the tedious task of tuning the optimizer's hyperparameters, such as the learning rate. There exist many techniques for automated hyperparameter optimization, but they typically introduce even more hyperparameters to control the hyperparameter optimization process. We propose to instead learn the hyperparameters themselves by gradient descent, and furthermore to learn the hyper-hyperparameters by gradient descent as well, and so on ad infinitum. As these towers of gradient-based optimizers grow, they become significantly less sensitive to the choice of top-level hyperparameters, hence decreasing the burden on the user to search for optimal values.
View paper on
 OpenReview
OpenReview