 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Align Multi-Camera Domain for Unsupervised Video Person Re-Identification
Paper and Code
Oct 21, 2019
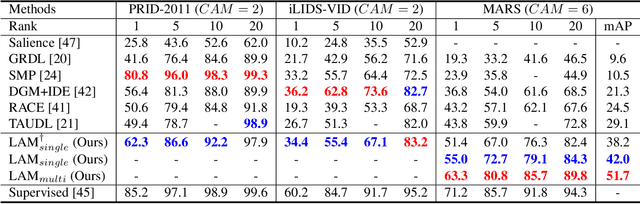
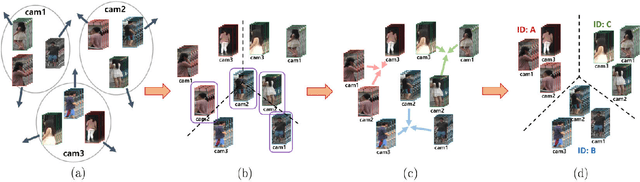

Most video person re-identification (re-ID) methods are mainly based on supervised learning, which requires laborious cross-camera ID labeling. Due to this limit, it is difficult to increase the number of cameras for constructing a large camera network. In this paper, we address the person ID labeling issue by presenting novel deep representation learning without ID information across multiple cameras. Specifically, our method consists of both inter- and intra camera feature learning techniques. We maximize feature distances between people within a camera. At the same time, considering each camera as a different domain, we apply domain adversarial learning across multiple camera views for minimizing camera domain discrepancy. To further enhance our approach, we propose person part-level adaptation to effectively perform multi-camera domain invariant feature learning at different spatial regions. We carry out comprehensive experiments on four public re-ID datasets (i.e., PRID-2011, iLIDS-VID, MARS, and Market1501). Our method outperforms state-of-the-art methods by a large margin of about 20% in terms of rank-1 accuracy on the large-scale MARS dataset.