 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Co-attention Recurrent Neural Networks for Human-Skeleton Motion Prediction
Paper and Code
Oct 01, 2019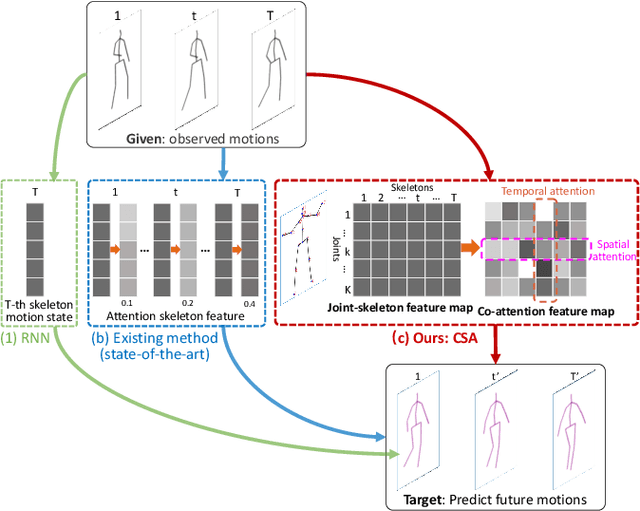

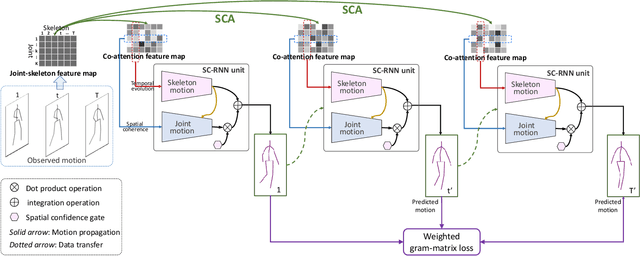
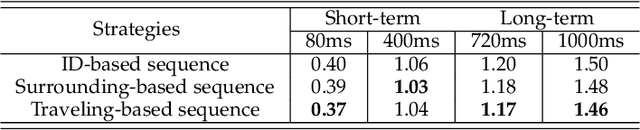
Human motion prediction aims to generate future motions based on the observed human motions. Witnessing the success of Recurrent Neural Networks (RNN) in modeling the sequential data, recent works utilize RNN to model human-skeleton motion on the observed motion sequence and predict future human motions. However, these methods did not consider the existence of the spatial coherence among joints and the temporal evolution among skeletons, which reflects the crucial characteristics of human motion in spatiotemporal space. To this end, we propose a novel Skeleton-joint Co-attention Recurrent Neural Networks (SC-RNN) to capture the spatial coherence among joints, and the temporal evolution among skeletons simultaneously on a skeleton-joint co-attention feature map in spatiotemporal space. First, a skeleton-joint feature map is constructed as the representation of the observed motion sequence. Second, we design a new Skeleton-joint Co-Attention (SCA) mechanism to dynamically learn a skeleton-joint co-attention feature map of this skeleton-joint feature map, which can refine the useful observed motion information to predict one future motion. Third, a variant of GRU embedded with SCA collaboratively models the human-skeleton motion and human-joint motion in spatiotemporal space by regarding the skeleton-joint co-attention feature map as the motion context. Experimental results on human motion prediction demonstrate the proposed method outperforms the related methods.