 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Ensemble Learning for News Stance Detection
Paper and Code

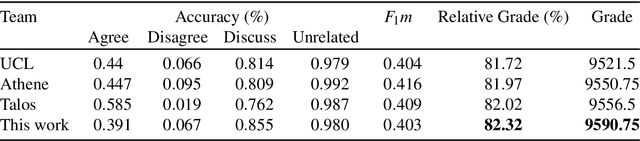
Stance detection in fake news is an important component in news veracity assessment because this process helps fact-checking by understanding stance to a central claim from different information sources. The Fake News Challenge Stage 1 (FNC-1) held in 2017 was setup for this purpose, which involves estimating the stance of a news article body relative to a given headline. This thesis starts from the error analysis for the three top-performing systems in FNC-1. Based on the analysis, a simple but tough-to-beat Multilayer Perceptron system is chosen as the baseline. Afterwards, three approaches are explored to improve baseline.The first approach explores the possibility of improving the prediction accuracy by adding extra keywords features when training a model, where keywords are converted to an indicator vector and then concatenated to the baseline features. A list of keywords is manually selected based on the error analysis, which may best reflect some characteristics of fake news titles and bodies. To make this selection process automatically, three algorithms are created based on Mutual Information (MI) theory: keywords generator based on MI stance class, MI customised class, and Pointwise MI algorithm. The second approach is based on word embedding, where word2vec model is introduced and two document similarities calculation algorithms are implemented: wor2vec cosine similarity and WMD distance. The third approach is ensemble learning. Different models are configured together with two continuous outputs combining algorithms. The 10-fold cross validation reveals that the ensemble of three neural network models trained from simple bag-of-words features gives the best performance. It is therefore selected to compete in FNC-1. After hyperparameters fine tuning, the selected deep ensemble model beats the FNC-1 winner team by a remarkable 34.25 marks under FNC-1's evaluation metric.