 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS: Dialectal Arabic Transcription System
Paper and Code
Sep 26, 2019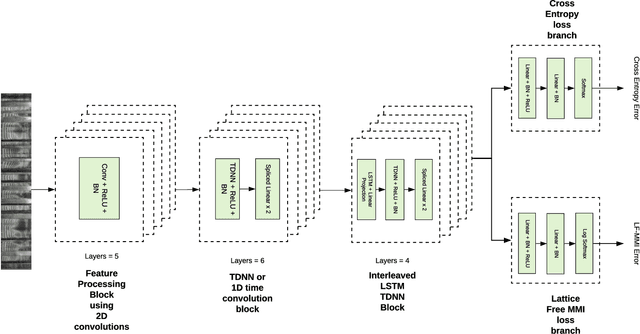
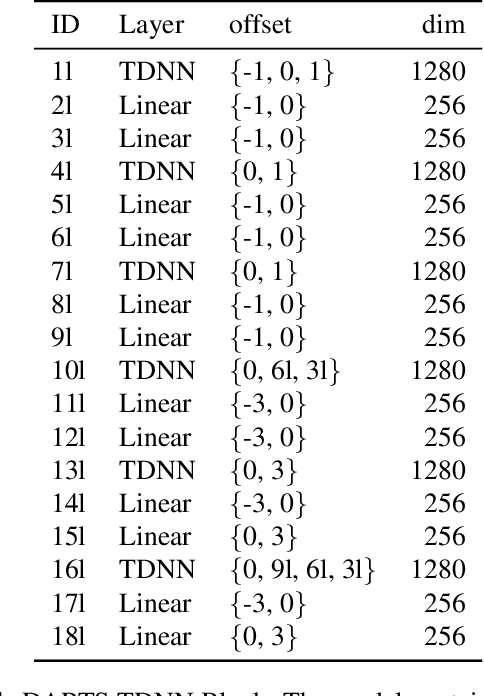
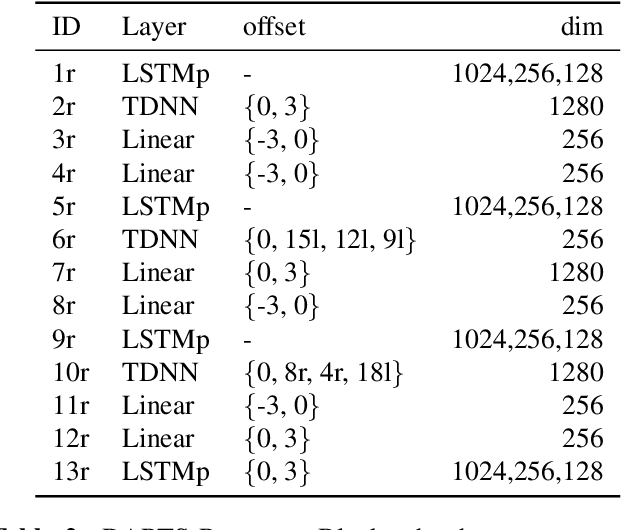

We present the speech to text transcription system, called DARTS, for low resource Egyptian Arabic dialect. We analyze the following; transfer learning from high resource broadcast domain to low-resource dialectal domain and semi-supervised learning where we use in-domain unlabeled audio data collected from YouTube. Key features of our system are: A deep neural network acoustic model that consists of a front end Convolutional Neural Network (CNN) followed by several layers of Time Delayed Neural Network (TDNN) and Long-Short Term Memory Recurrent Neural Network (LSTM); sequence discriminative training of the acoustic model; n-gram and recurrent neural network language model for decoding and N-best list rescoring. We show that a simple transfer learning method can achieve good results. The results are further improved by using unlabeled data from YouTube in a semi-supervised setup. Various systems are combined to give the final system that achieves the lowest word error on on the community standard Egyptian-Arabic speech dataset (MGB-3).