 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Metric for Automated Conversational Dialogue System Evaluation and Improvement
Paper and Code
Sep 26, 2019
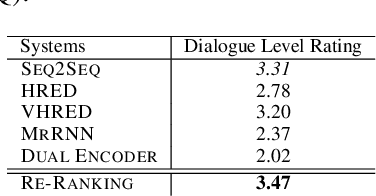
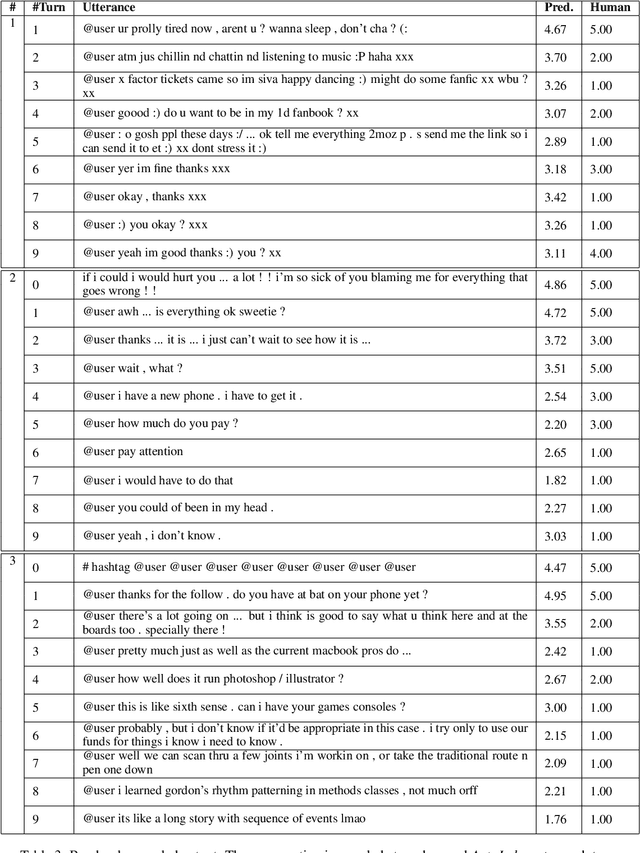
We present "AutoJudge", an automated evaluation method for conversational dialogue systems. The method works by first generating dialogues based on self-talk, i.e. dialogue systems talking to itself. Then, it uses human ratings on these dialogues to train an automated judgement model. Our experiments show that AutoJudge correlates well with the human ratings and can be used to automatically evaluate dialogue systems, even in deployed systems. In a second part, we attempt to apply AutoJudge to improve existing systems. This works well for re-ranking a set of candidate utterances. However, our experiments show that AutoJudge cannot be applied as reward for reinforcement learning, although the metric can distinguish good from bad dialogues. We discuss potential reasons, but state here already that this is still an open question for further research.