 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Communities: A Text Classification Model with Automated Labeling Process Using Network Community Detection
Paper and Code
Sep 25, 2019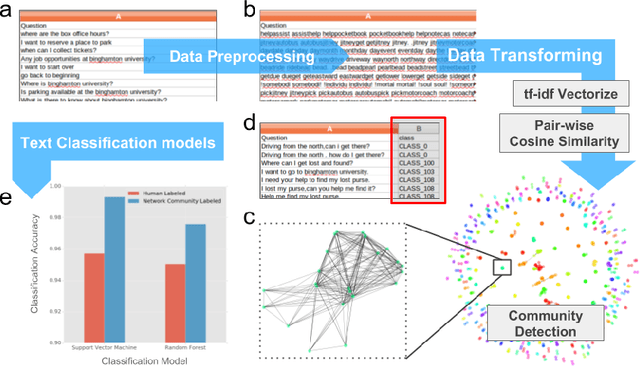
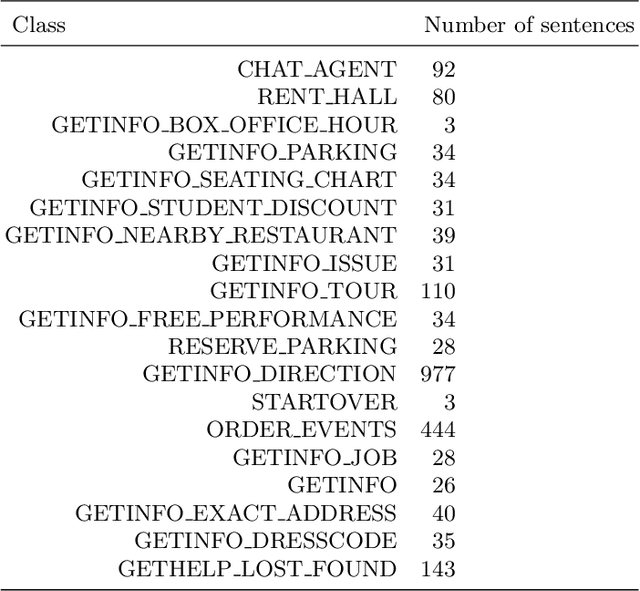
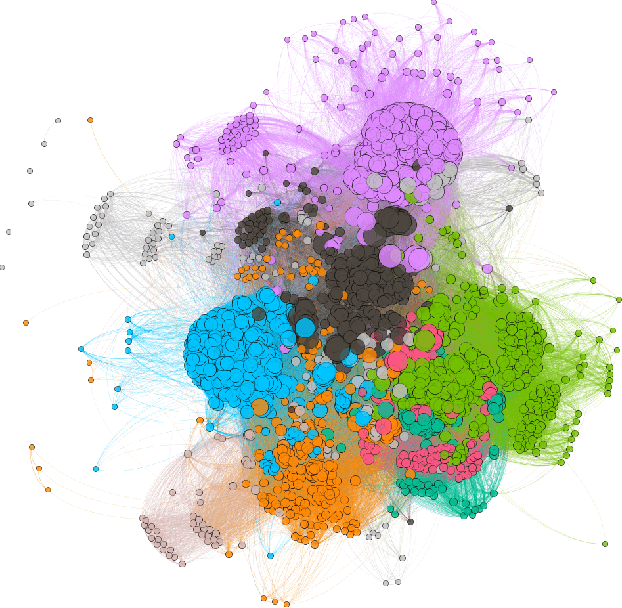
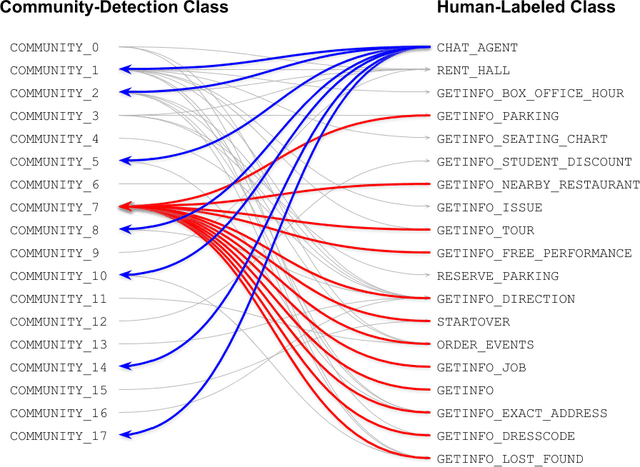
The text classification is one of the most critical areas in machine learning and artificial intelligence research. It has been actively adopted in many business applications such as conversational intelligence systems, news articles categorizations, sentiment analysis, emotion detection systems, and many other recommendation systems in our daily life. One of the problems in supervised text classification models is that the models performance depend heavily on the quality of data labeling that are typically done by humans. In this study, we propose a new network community detection-based approach to automatically label and classify text data into multiclass value spaces. Specifically, we build a network with sentences as the network nodes and pairwise cosine similarities between TFIDF vector representations of the sentences as the network link weights. We use the Louvain method to detect the communities in the sentence network. We train and test Support vector machine and Random forest models on both the human labeled data and network community detection labeled data. Results showed that models with the data labeled by network community detection outperformed the models with the human-labeled data by 2.68-3.75% of classification accuracy. Our method may help development of a more accurate conversational intelligence system and other text classification systems.