 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a New Understanding of the Training of Neural Networks with Mislabeled Training Data
Paper and Code
Sep 18, 2019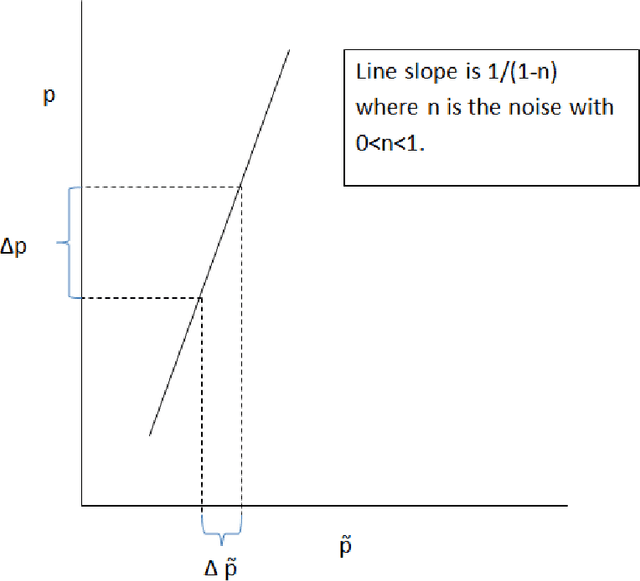
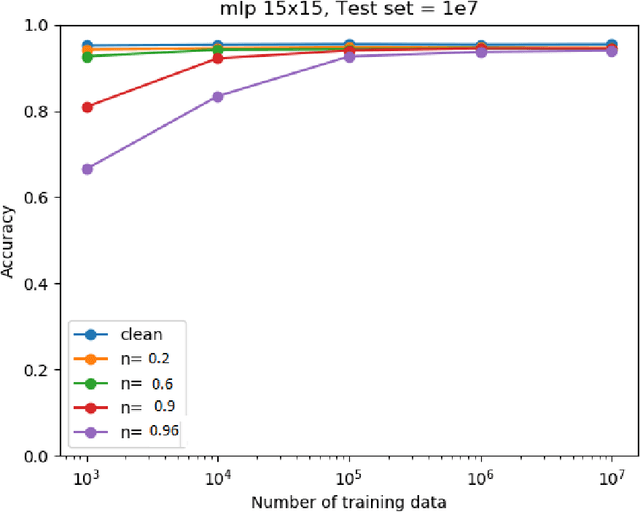
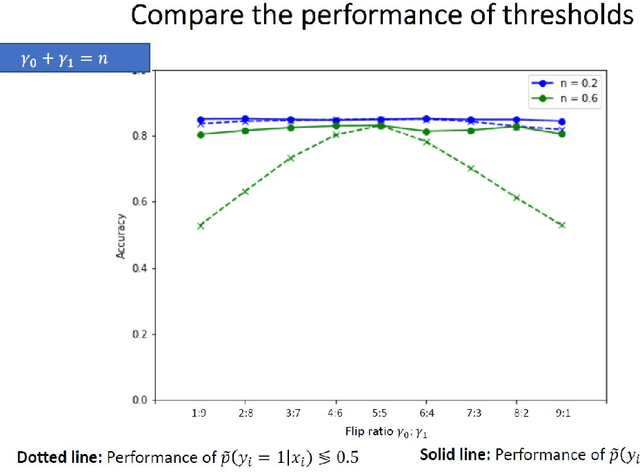
We investigate the problem of machine learning with mislabeled training data. We try to make the effects of mislabeled training better understood through analysis of the basic model and equations that characterize the problem. This includes results about the ability of the noisy model to make the same decisions as the clean model and the effects of noise on model performance. In addition to providing better insights we also are able to show that the Maximum Likelihood (ML) estimate of the parameters of the noisy model determine those of the clean model. This property is obtained through the use of the ML invariance property and leads to an approach to developing a classifier when training has been mislabeled: namely train the classifier on noisy data and adjust the decision threshold based on the noise levels and/or class priors. We show how our approach to mislabeled training works with multi-layered perceptrons (MLPs).