 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Conversion of Machine Learning Pipelines
Mar 26, 2026Transfer learning and knowledge distillation has recently gained a lot of attention in the deep learning community. One transfer approach, the student-teacher learning, has been shown to successfully create ``small'' student neural networks that mimic the performance of a much bigger and more complex ``teacher'' networks. In this paper, we investigate an extension to this approach and transfer from a non-neural-based machine learning pipeline as teacher to a neural network (NN) student, which would allow for joint optimization of the various pipeline components and a single unified inference engine for multiple ML tasks. In particular, we explore replacing the random forest classifier by transfer learning to a student NN. We experimented with various NN topologies on 100 OpenML tasks in which random forest has been one of the best solutions. Our results show that for the majority of the tasks, the student NN can indeed mimic the teacher if one can select the right NN hyper-parameters. We also investigated the use of random forest for selecting the right NN hyper-parameters.
Learning from Noisy Labels with Noise Modeling Network
May 01, 2020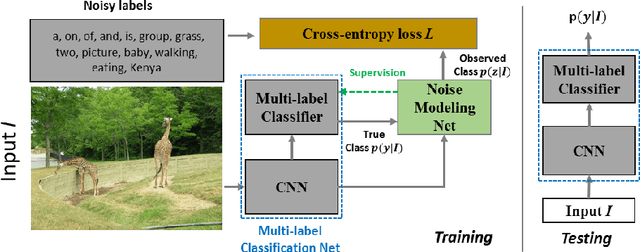
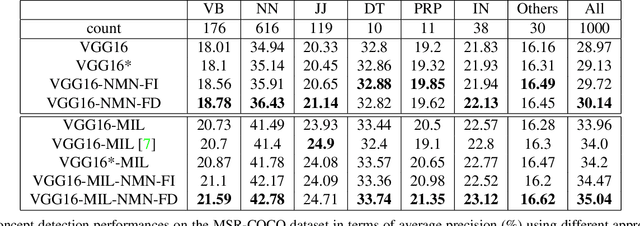
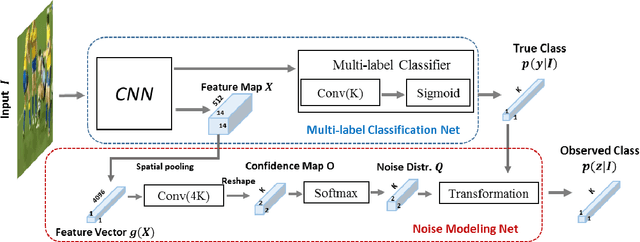
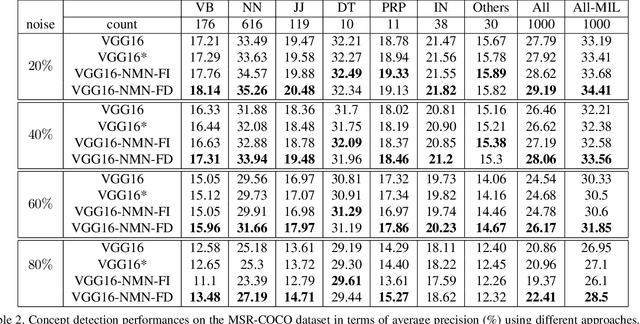
Multi-label image classification has generated significant interest in recent years and the performance of such systems often suffers from the not so infrequent occurrence of incorrect or missing labels in the training data. In this paper, we extend the state-of the-art of training classifiers to jointly deal with both forms of errorful data. We accomplish this by modeling noisy and missing labels in multi-label images with a new Noise Modeling Network (NMN) that follows our convolutional neural network (CNN), integrates with it, forming an end-to-end deep learning system, which can jointly learn the noise distribution and CNN parameters. The NMN learns the distribution of noise patterns directly from the noisy data without the need for any clean training data. The NMN can model label noise that depends only on the true label or is also dependent on the image features. We show that the integrated NMN/CNN learning system consistently improves the classification performance, for different levels of label noise, on the MSR-COCO dataset and MSR-VTT dataset. We also show that noise performance improvements are obtained when multiple instance learning methods are used.
Towards a New Understanding of the Training of Neural Networks with Mislabeled Training Data
Sep 18, 2019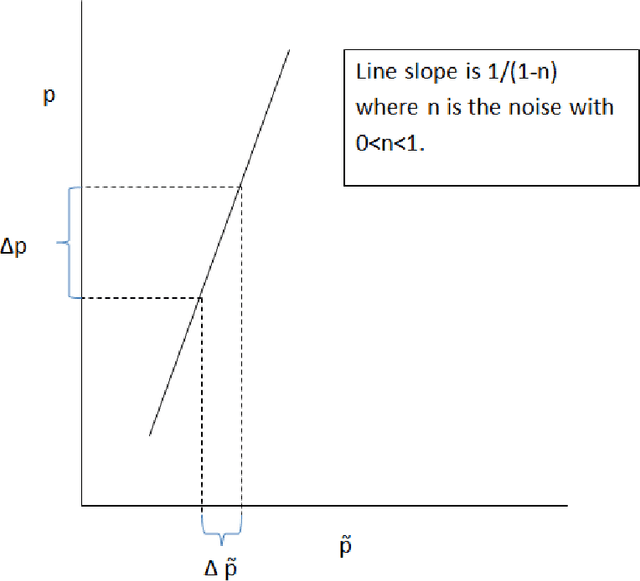
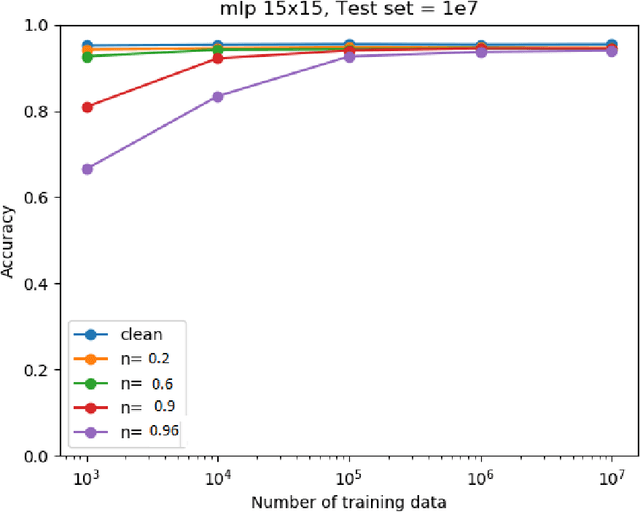
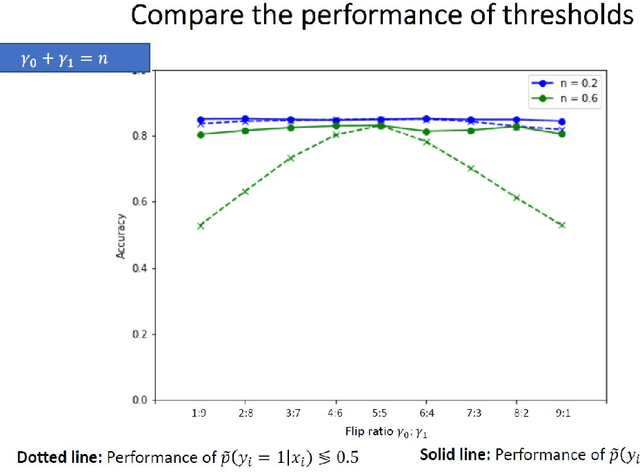
We investigate the problem of machine learning with mislabeled training data. We try to make the effects of mislabeled training better understood through analysis of the basic model and equations that characterize the problem. This includes results about the ability of the noisy model to make the same decisions as the clean model and the effects of noise on model performance. In addition to providing better insights we also are able to show that the Maximum Likelihood (ML) estimate of the parameters of the noisy model determine those of the clean model. This property is obtained through the use of the ML invariance property and leads to an approach to developing a classifier when training has been mislabeled: namely train the classifier on noisy data and adjust the decision threshold based on the noise levels and/or class priors. We show how our approach to mislabeled training works with multi-layered perceptrons (MLPs).