 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Speech Recognition and Speaker Diarization for Monaural Dialogue Recordings with Target-Speaker Acoustic Models
Paper and Code
Sep 17, 2019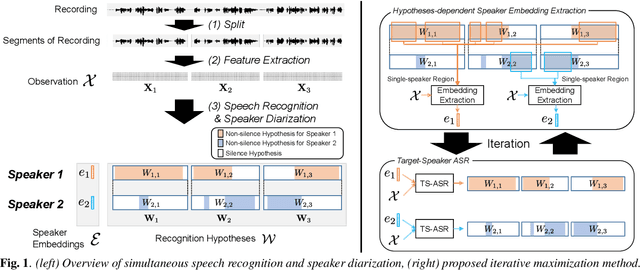
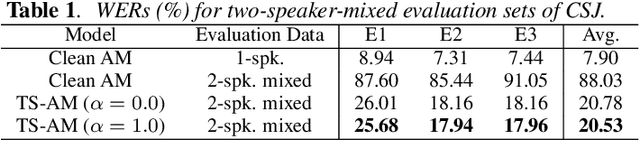
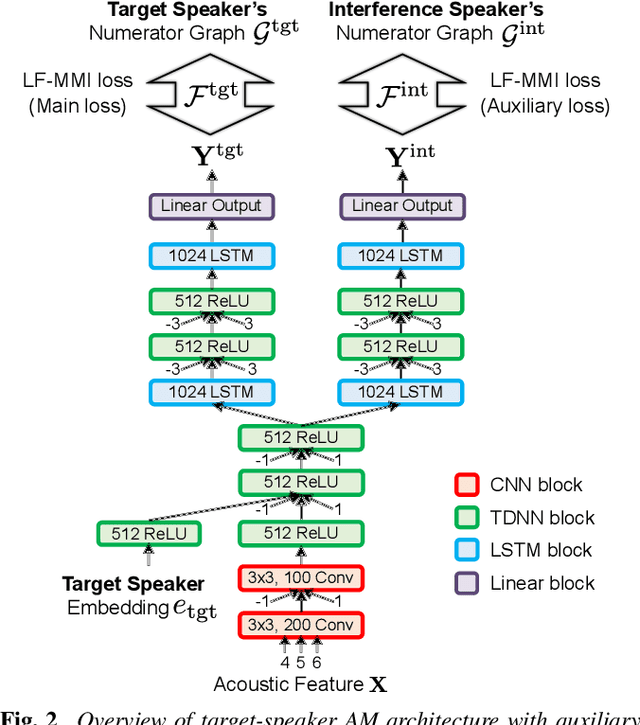
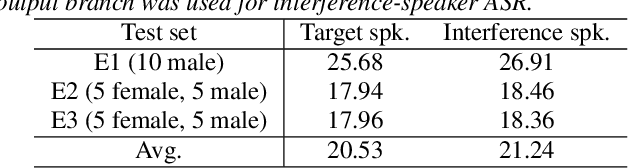
This paper investigates the use of target-speaker automatic speech recognition (TS-ASR) for simultaneous speech recognition and speaker diarization of single-channel dialogue recordings. TS-ASR is a technique to automatically extract and recognize only the speech of a target speaker given a short sample utterance of that speaker. One obvious drawback of TS-ASR is that it cannot be used when the speakers in the recordings are unknown because it requires a sample of the target speakers in advance of decoding. To remove this limitation, we propose an iterative method, in which (i) the estimation of speaker embeddings and (ii) TS-ASR based on the estimated speaker embeddings are alternately executed. We evaluated the proposed method by using very challenging dialogue recordings in which the speaker overlap ratio was over 20%. We confirmed that the proposed method significantly reduced both the word error rate (WER) and diarization error rate (DER). Our proposed method combined with i-vector speaker embeddings ultimately achieved a WER that differed by only 2.1 % from that of TS-ASR given oracle speaker embeddings. Furthermore, our method can solve speaker diarization simultaneously as a by-product and achieved better DER than that of the conventional clustering-based speaker diarization method based on i-vector.