 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view and Multi-source Transfers in Neural Topic Modeling with Pretrained Topic and Word Embeddings
Paper and Code
Sep 17, 2019
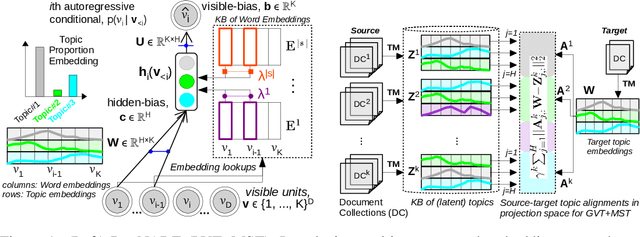
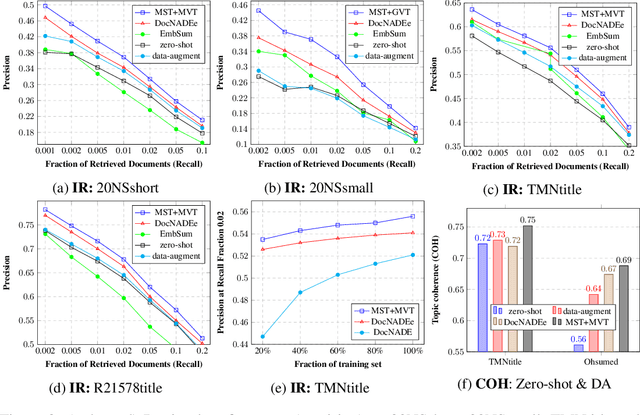
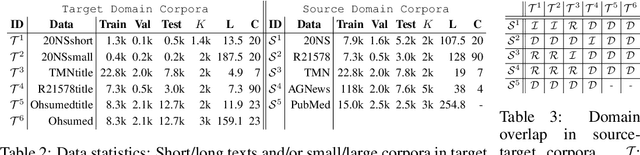
Though word embeddings and topics are complementary representations, several past works have only used pre-trained word embeddings in (neural) topic modeling to address data sparsity problem in short text or small collection of documents. However, no prior work has employed (pre-trained latent) topics in transfer learning paradigm. In this paper, we propose an approach to (1) perform knowledge transfer using latent topics obtained from a large source corpus, and (2) jointly transfer knowledge via the two representations (or views) in neural topic modeling to improve topic quality, better deal with polysemy and data sparsity issues in a target corpus. In doing so, we first accumulate topics and word representations from one or many source corpora to build a pool of topics and word vectors. Then, we identify one or multiple relevant source domain(s) and take advantage of corresponding topics and word features via the respective pools to guide meaningful learning in the sparse target domain. We quantify the quality of topic and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. We have demonstrated the state-of-the-art results on topic modeling with the proposed framework.