 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple but effective techniques to reduce biases
Paper and Code
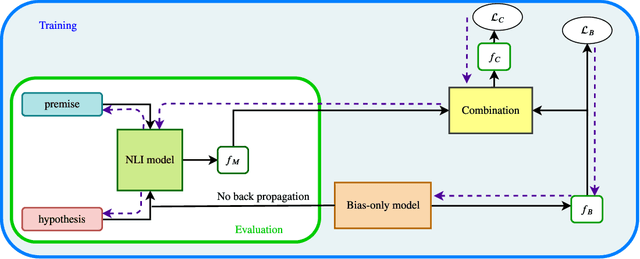
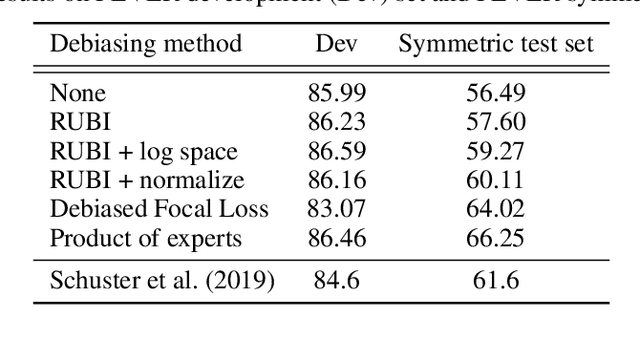
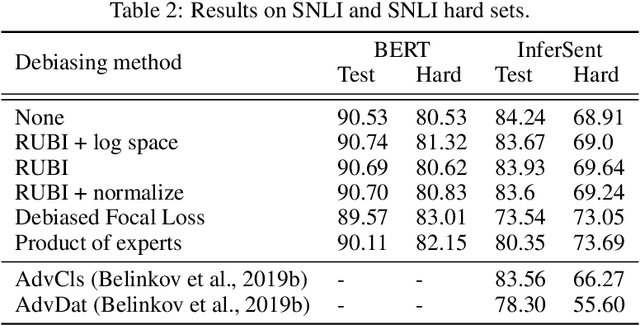
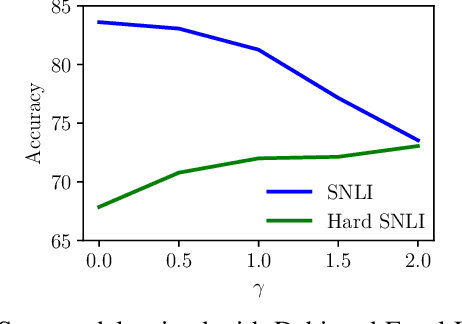
There have been several studies recently showing that strong natural language understanding (NLU) models are prone to relying on unwanted dataset biases without learning the underlying task, resulting in models which fail to generalize to out-of-domain datasets, and are likely to perform poorly in real-world scenarios. We propose several learning strategies to train neural models which are more robust to such biases and transfer better to out-of-domain datasets. We introduce an additional lightweight bias-only model which learns dataset biases and uses its prediction to adjust the loss of the base model to reduce the biases. In other words, our methods down-weight the importance of the biased examples, and focus training on hard examples, i.e. examples that cannot be correctly classified by only relying on biases. Our approaches are model agnostic and simple to implement. We experiment on large-scale natural language inference and fact verification datasets and their out-of-domain datasets and show that our debiased models significantly improve the robustness in all settings, including gaining 9.76 points on the FEVER symmetric evaluation dataset, 5.45 on the HANS dataset and 4.78 points on the SNLI hard set. These datasets are specifically designed to assess the robustness of models in the out-of-domain setting where typical biases in the training data do not exist in the evaluation set.