 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neural Speaker Diarization with Self-attention
Paper and Code
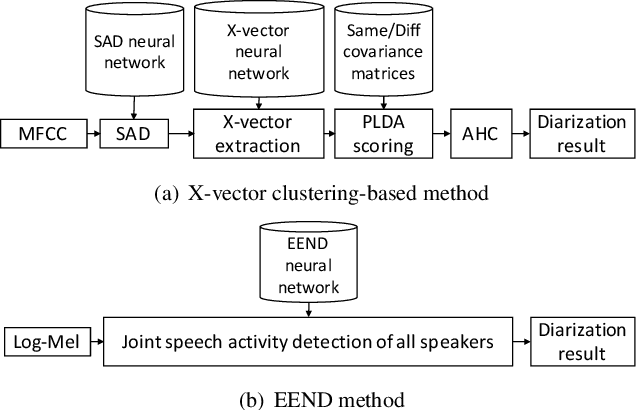
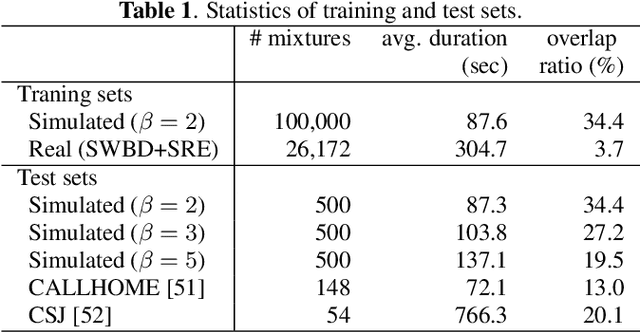
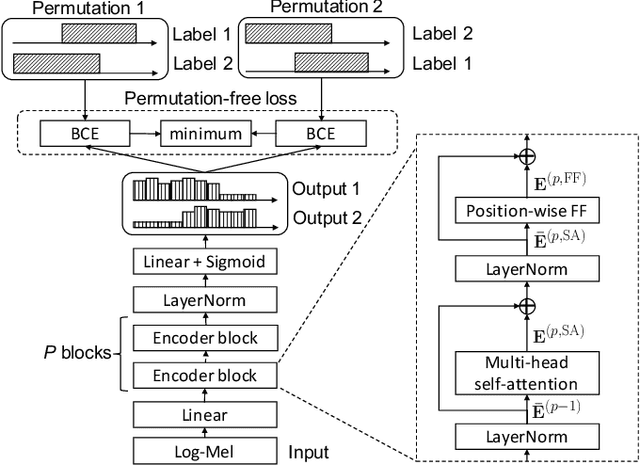
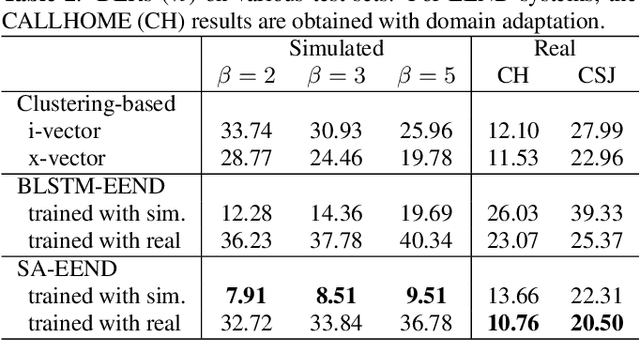
Speaker diarization has been mainly developed based on the clustering of speaker embeddings. However, the clustering-based approach has two major problems; i.e., (i) it is not optimized to minimize diarization errors directly, and (ii) it cannot handle speaker overlaps correctly. To solve these problems, the End-to-End Neural Diarization (EEND), in which a bidirectional long short-term memory (BLSTM) network directly outputs speaker diarization results given a multi-talker recording, was recently proposed. In this study, we enhance EEND by introducing self-attention blocks instead of BLSTM blocks. In contrast to BLSTM, which is conditioned only on its previous and next hidden states, self-attention is directly conditioned on all the other frames, making it much suitable for dealing with the speaker diarization problem. We evaluated our proposed method on simulated mixtures, real telephone calls, and real dialogue recordings. The experimental results revealed that the self-attention was the key to achieving good performance and that our proposed method performed significantly better than the conventional BLSTM-based method. Our method was even better than that of the state-of-the-art x-vector clustering-based method. Finally, by visualizing the latent representation, we show that the self-attention can capture global speaker characteristics in addition to local speech activity dynamics. Our source code is available online at https://github.com/hitachi-speech/EEND.