 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Zero-Shot Learning: A Conditional Visual Classification Perspective
Paper and Code
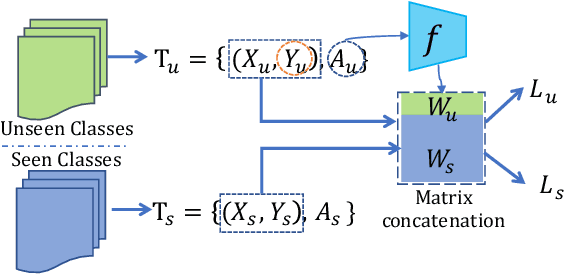
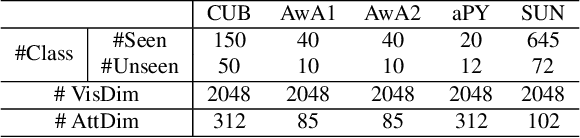
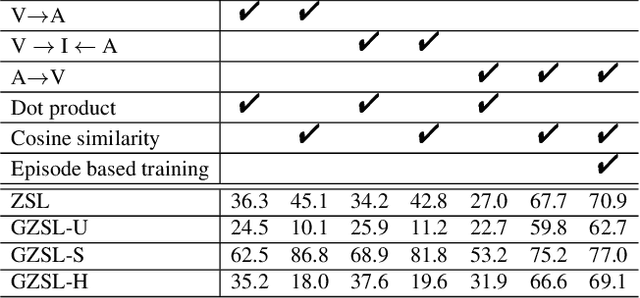
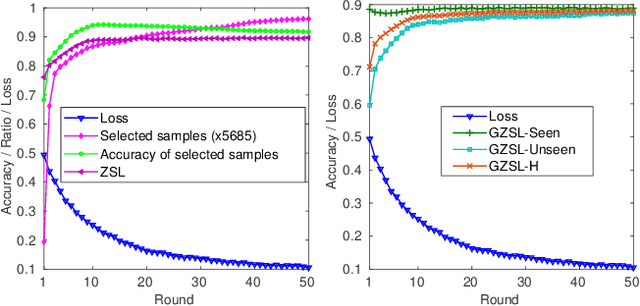
Zero-shot learning (ZSL) aims to recognize instances of unseen classes solely based on the semantic descriptions of the classes. Existing algorithms usually formulate it as a semantic-visual correspondence problem, by learning mappings from one feature space to the other. Despite being reasonable, previous approaches essentially discard the highly precious discriminative power of visual features in an implicit way, and thus produce undesirable results. We instead reformulate ZSL as a conditioned visual classification problem, i.e., classifying visual features based on the classifiers learned from the semantic descriptions. With this reformulation, we develop algorithms targeting various ZSL settings: For the conventional setting, we propose to train a deep neural network that directly generates visual feature classifiers from the semantic attributes with an episode-based training scheme; For the generalized setting, we concatenate the learned highly discriminative classifiers for seen classes and the generated classifiers for unseen classes to classify visual features of all classes; For the transductive setting, we exploit unlabeled data to effectively calibrate the classifier generator using a novel learning-without-forgetting self-training mechanism and guide the process by a robust generalized cross-entropy loss. Extensive experiments show that our proposed algorithms significantly outperform state-of-the-art methods by large margins on most benchmark datasets in all the ZSL settings.