 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neural Speaker Diarization with Permutation-Free Objectives
Paper and Code
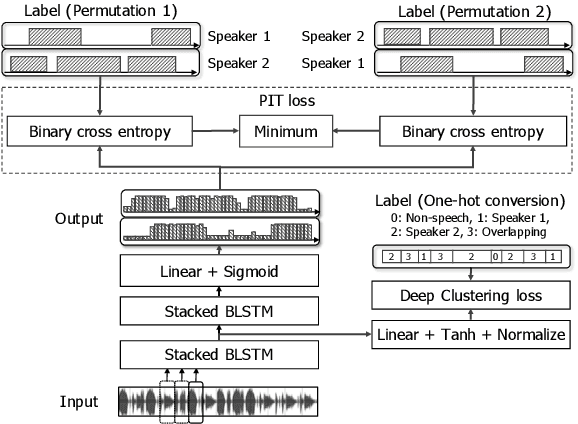
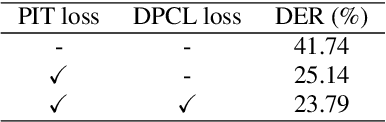
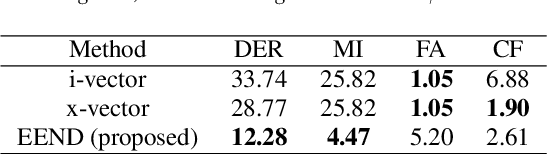
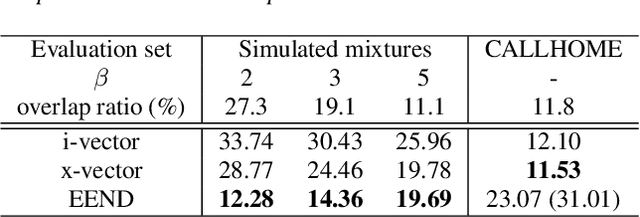
In this paper, we propose a novel end-to-end neural-network-based speaker diarization method. Unlike most existing methods, our proposed method does not have separate modules for extraction and clustering of speaker representations. Instead, our model has a single neural network that directly outputs speaker diarization results. To realize such a model, we formulate the speaker diarization problem as a multi-label classification problem, and introduces a permutation-free objective function to directly minimize diarization errors without being suffered from the speaker-label permutation problem. Besides its end-to-end simplicity, the proposed method also benefits from being able to explicitly handle overlapping speech during training and inference. Because of the benefit, our model can be easily trained/adapted with real-recorded multi-speaker conversations just by feeding the corresponding multi-speaker segment labels. We evaluated the proposed method on simulated speech mixtures. The proposed method achieved diarization error rate of 12.28%, while a conventional clustering-based system produced diarization error rate of 28.77%. Furthermore, the domain adaptation with real-recorded speech provided 25.6% relative improvement on the CALLHOME dataset. Our source code is available online at https://github.com/hitachi-speech/EEND.