 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Linear Programming: Dual Convergence, New Algorithms, and Regret Bounds
Paper and Code
Sep 12, 2019
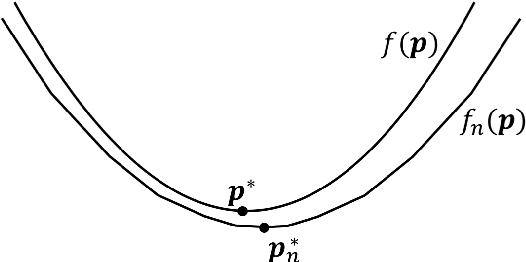
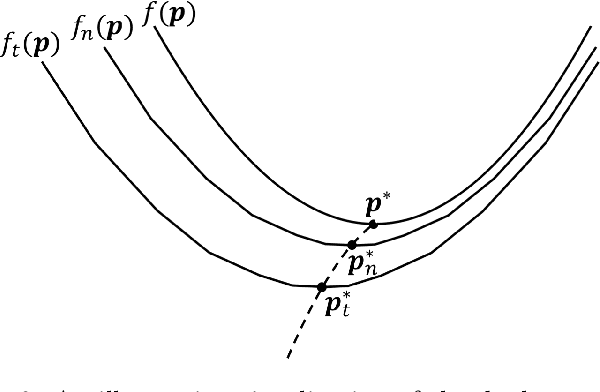

We study an online linear programming (OLP) problem under a random input model in which the columns of the constraint matrix along with the corresponding coefficients in the objective function are generated i.i.d. from an unknown distribution and revealed sequentially over time. Virtually all current online algorithms were based on learning the dual optimal solutions/prices of the linear programs (LP), and their analyses were focused on the aggregate objective value and solving the packing LP where all coefficients in the constraint matrix and objective are nonnegative. However, two major open questions are: (i) Does the set of LP optimal dual prices of OLP converge to those of the "offline" LP, and (ii) Could the results be extended to general LP problems where the coefficients can be either positive or negative. We resolve these two questions by establishing convergence results for the dual prices under moderate regularity conditions for general LP problems. Then we propose a new type of OLP algorithm, Action-History-Dependent Learning Algorithm, which improves the previous algorithm performances by taking into account the past input data as well as and decisions/actions already made. We derive an $O(\log n \log \log n)$ regret bound for the proposed algorithm, against the $O(\sqrt{n})$ bound for typical dual-price learning algorithms, and show that no dual-based thresholding algorithm achieves a worst-case regret smaller than $O(\log n)$, where n is the number of decision variables. Numerical experiments demonstrate the superior performance of the proposed algorithms and the effectiveness of our action-history-dependent design. Our results also indicate that, for solving online optimization problems with constraints, it's better to utilize a non-stationary policy rather than the stationary one.