 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Hybrid Approach for Textual Document Classification
Paper and Code
Sep 12, 2019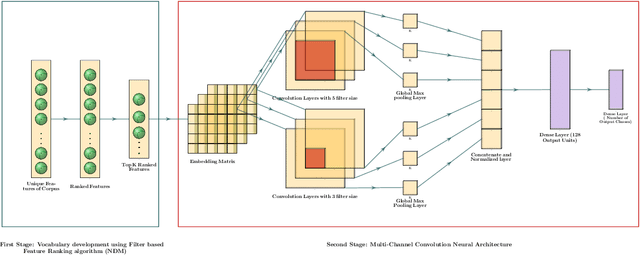
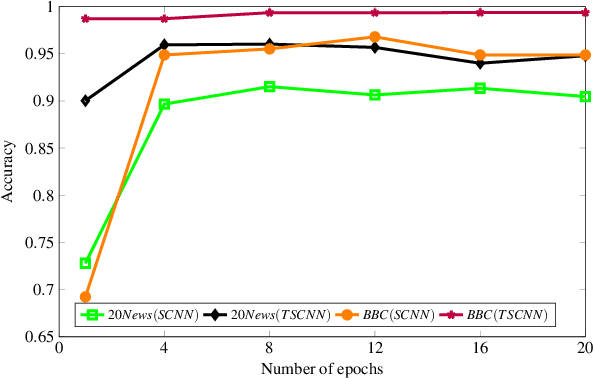
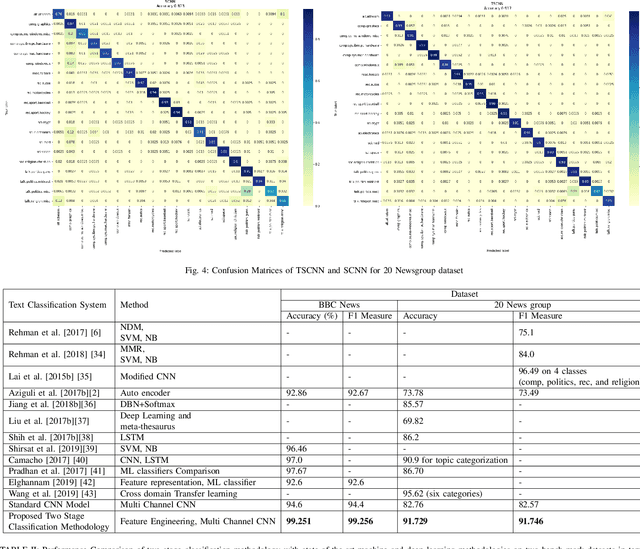
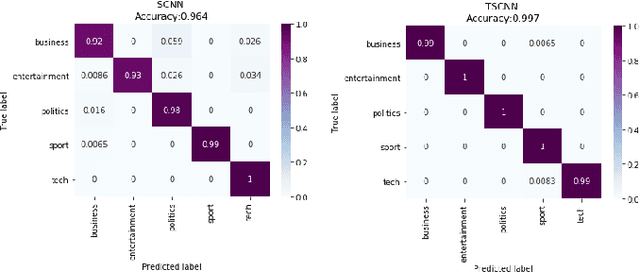
Text document classification is an important task for diverse natural language processing based applications. Traditional machine learning approaches mainly focused on reducing dimensionality of textual data to perform classification. This although improved the overall classification accuracy, the classifiers still faced sparsity problem due to lack of better data representation techniques. Deep learning based text document classification, on the other hand, benefitted greatly from the invention of word embeddings that have solved the sparsity problem and researchers focus mainly remained on the development of deep architectures. Deeper architectures, however, learn some redundant features that limit the performance of deep learning based solutions. In this paper, we propose a two stage text document classification methodology which combines traditional feature engineering with automatic feature engineering (using deep learning). The proposed methodology comprises a filter based feature selection (FSE) algorithm followed by a deep convolutional neural network. This methodology is evaluated on the two most commonly used public datasets, i.e., 20 Newsgroups data and BBC news data. Evaluation results reveal that the proposed methodology outperforms the state-of-the-art of both the (traditional) machine learning and deep learning based text document classification methodologies with a significant margin of 7.7% on 20 Newsgroups and 6.6% on BBC news datasets.