 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDI-Sandwich2: RNN-based Hierarchical Multi-modal Fusion Generation VAE networks for multi-track symbolic music generation
Paper and Code
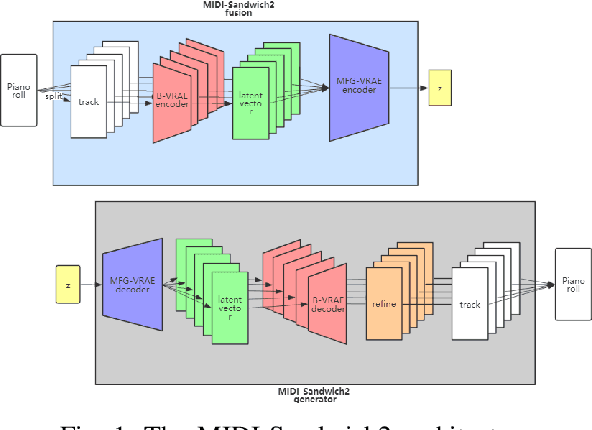

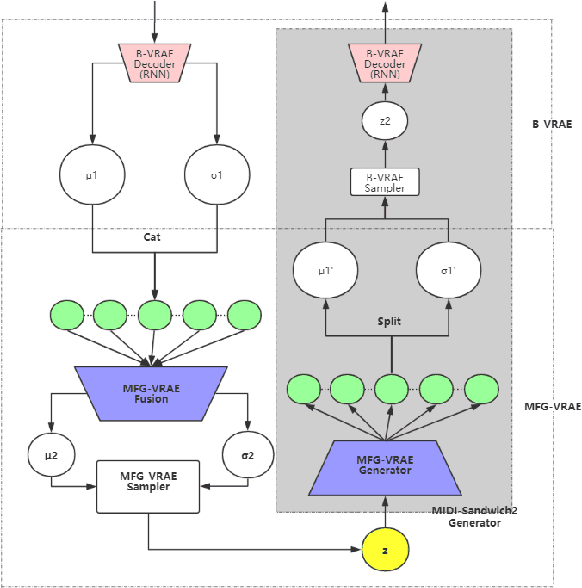
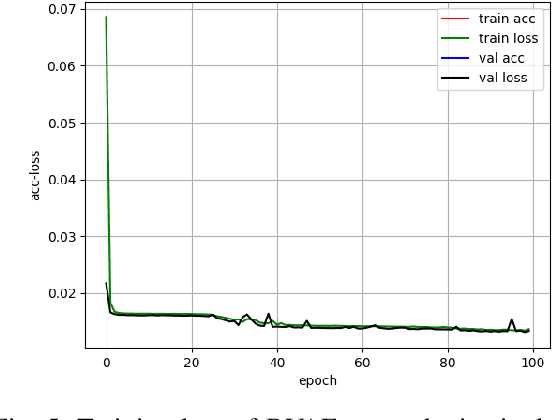
Currently, almost all the multi-track music generation models use the Convolutional Neural Network (CNN) to build the generative model, while the Recurrent Neural Network (RNN) based models can not be applied in this task. In view of the above problem, this paper proposes a RNN-based Hierarchical Multi-modal Fusion Generation Variational Autoencoder (VAE) network, MIDI-Sandwich2, for multi-track symbolic music generation. Inspired by VQ-VAE2, MIDI-Sandwich2 expands the dimension of the original hierarchical model by using multiple independent Binary Variational Autoencoder (BVAE) models without sharing weights to process the information of each track. Then, with multi-modal fusion technology, the upper layer named Multi-modal Fusion Generation VAE (MFG-VAE) combines the latent space vectors generated by the respective tracks, and uses the decoder to perform the ascending dimension reconstruction to simulate the inverse operation of multi-modal fusion, multi-modal generation, so as to realize the RNN-based multi-track symbolic music generation. For the multi-track format pianoroll, we also improve the output binarization method of MuseGAN, which solves the problem that the refinement step of the original scheme is difficult to differentiate and the gradient is hard to descent, making the generated song more expressive. The model is validated on the Lakh Pianoroll Dataset (LPD) multi-track dataset. Compared to the MuseGAN, MIDI-Sandwich2 can not only generate harmonious multi-track music, the generation quality is also close to the state of the art level. At the same time, by using the VAE to restore songs, the semi-generated songs reproduced by the MIDI-Sandwich2 are more beautiful than the pure autogeneration music generated by MuseGAN. Both the code and the audition audio samples are open source on https://github.com/LiangHsia/MIDI-S2.