 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversely Stale Parameters for Efficient Training of CNNs
Paper and Code
Sep 24, 2019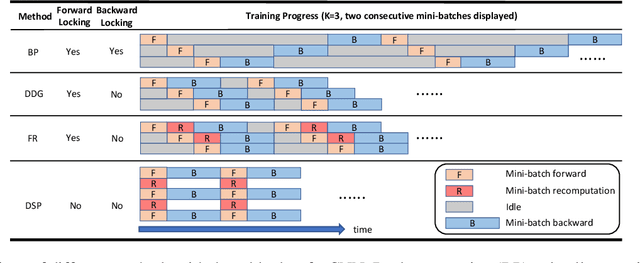
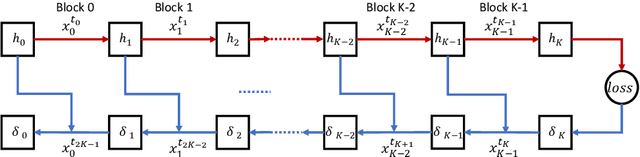
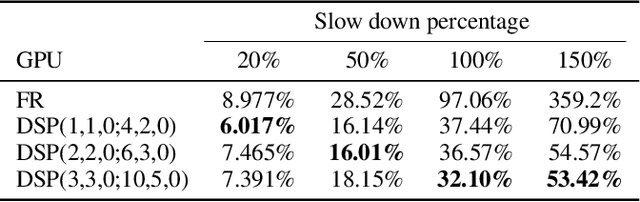
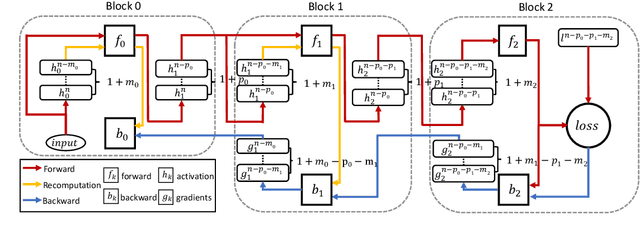
The backpropagation algorithm is the most popular algorithm training neural networks nowadays. However, it suffers from the forward locking, backward locking and update locking problems, especially when a neural network is so large that its layers are distributed across multiple devices. Existing solutions either can only handle one locking problem or lead to severe accuracy loss or memory inefficiency. Moreover, none of them consider the straggler problem among devices. In this paper, we propose Layer-wise Staleness and a novel efficient training algorithm, Diversely Stale Parameters (DSP), which can address all these challenges without loss of accuracy nor memory issue. We also analyze the convergence of DSP with two popular gradient-based methods and prove that both of them are guaranteed to converge to critical points for non-convex problems. Finally, extensive experimental results on training deep convolutional neural networks demonstrate that our proposed DSP algorithm can achieve significant training speedup with stronger robustness and better generalization than compared methods.