 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Distributional Semantic Rewards for Abstractive Summarization
Paper and Code
Sep 10, 2019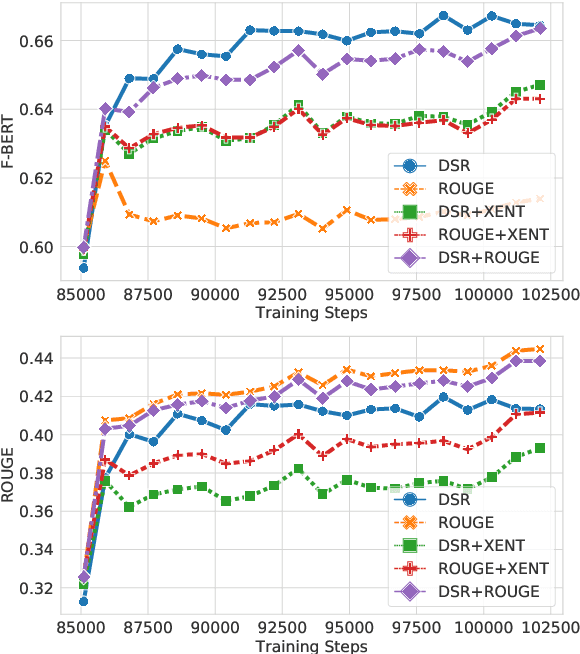
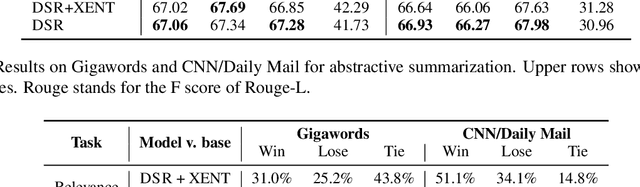
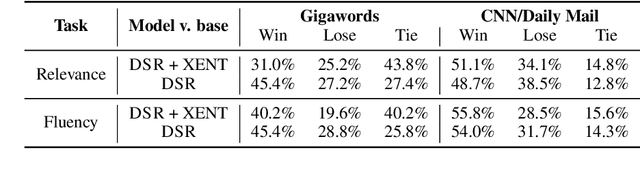
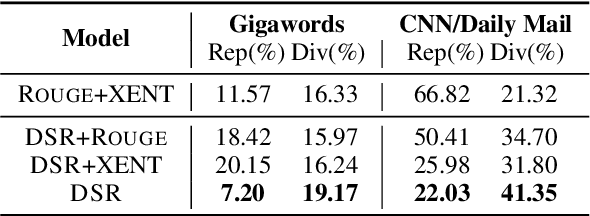
Deep reinforcement learning (RL) has been a commonly-used strategy for the abstractive summarization task to address both the exposure bias and non-differentiable task issues. However, the conventional reward Rouge-L simply looks for exact n-grams matches between candidates and annotated references, which inevitably makes the generated sentences repetitive and incoherent. In this paper, instead of Rouge-L, we explore the practicability of utilizing the distributional semantics to measure the matching degrees. With distributional semantics, sentence-level evaluation can be obtained, and semantically-correct phrases can also be generated without being limited to the surface form of the reference sentences. Human judgments on Gigaword and CNN/Daily Mail datasets show that our proposed distributional semantics reward (DSR) has distinct superiority in capturing the lexical and compositional diversity of natural language.