 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Modeling with Syntax-Aware Variational Autoencoders
Paper and Code
Aug 27, 2019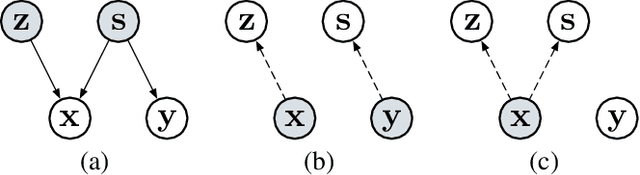
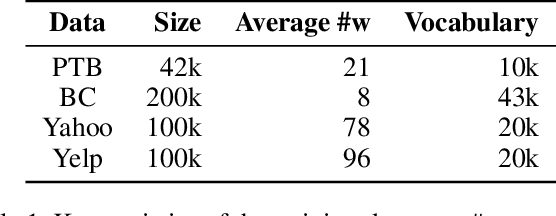
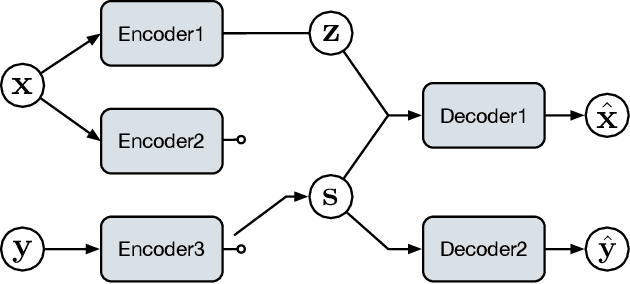
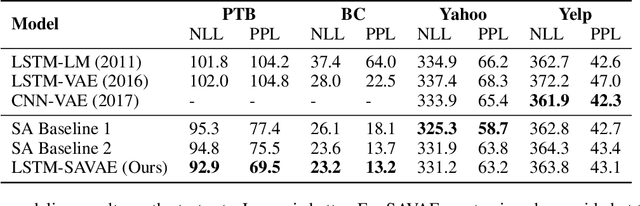
Syntactic information contains structures and rules about how text sentences are arranged. Incorporating syntax into text modeling methods can potentially benefit both representation learning and generation. Variational autoencoders (VAEs) are deep generative models that provide a probabilistic way to describe observations in the latent space. When applied to text data, the latent representations are often unstructured. We propose syntax-aware variational autoencoders (SAVAEs) that dedicate a subspace in the latent dimensions dubbed syntactic latent to represent syntactic structures of sentences. SAVAEs are trained to infer syntactic latent from either text inputs or parsed syntax results as well as reconstruct original text with inferred latent variables. Experiments show that SAVAEs are able to achieve lower reconstruction loss on four different data sets. Furthermore, they are capable of generating examples with modified target syntax.