 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Community to Role-based Graph Embeddings
Paper and Code
Aug 22, 2019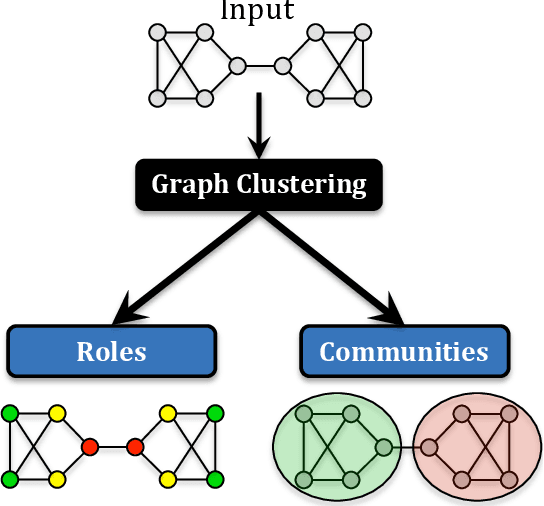

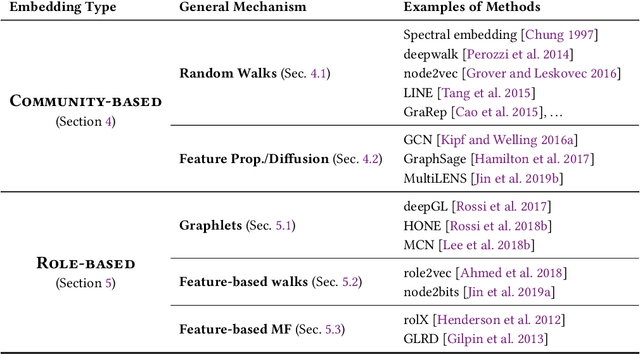
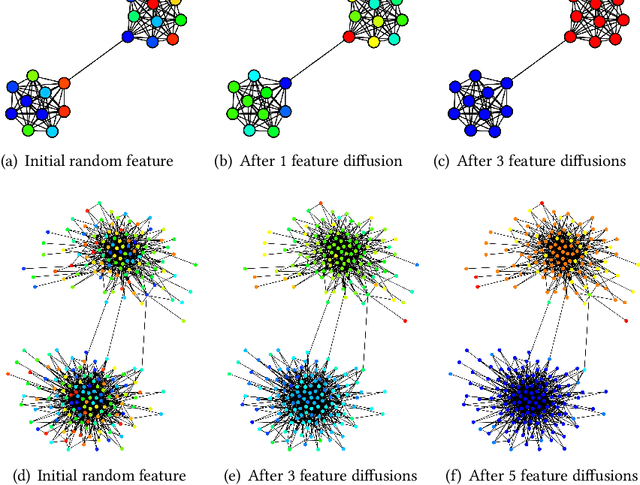
Roles are sets of structurally similar nodes that are more similar to nodes inside the set than outside, whereas communities are sets of nodes with more connections inside the set than outside (based on proximity/closeness, density). Roles and communities are fundamentally different but important complementary notions. Recently, the notion of roles has become increasingly important and has gained a lot of attention due to the proliferation of work on learning representations (node/edge embeddings) from graphs that preserve the notion of roles. Unfortunately, recent work has sometimes confused the notion of roles and communities leading to misleading or incorrect claims about the capabilities of network embedding methods. As such, this manuscript seeks to clarify the differences between roles and communities, and formalize the general mechanisms (e.g., random walks, feature diffusion) that give rise to community or role-based embeddings. We show mathematically why embedding methods based on these identified mechanisms are either community or role-based. These mechanisms are typically easy to identify and can help researchers quickly determine whether a method is more prone to learn community or role-based embeddings. Furthermore, they also serve as a basis for developing new and better methods for community or role-based embeddings. Finally, we analyze and discuss the applications and data characteristics where community or role-based embeddings are most appropriate.