 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising and Verification Cross-Layer Ensemble Against Black-box Adversarial Attacks
Paper and Code
Aug 21, 2019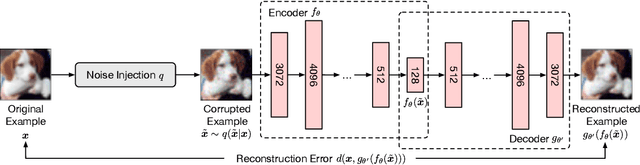

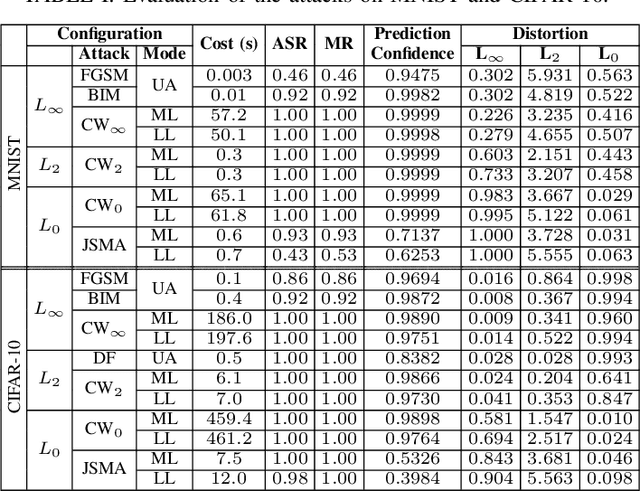
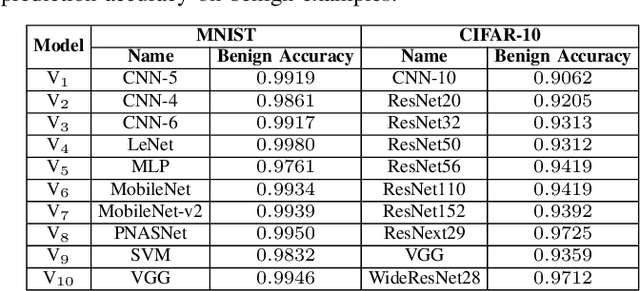
Deep neural networks (DNNs) have demonstrated impressive performance on many challenging machine learning tasks. However, DNNs are vulnerable to adversarial inputs generated by adding maliciously crafted perturbations to the benign inputs. As a growing number of attacks have been reported to generate adversarial inputs of varying sophistication, the defense-attack arms race has been accelerated. In this paper, we present MODEF, a cross-layer model diversity ensemble framework. MODEF intelligently combines unsupervised model denoising ensemble with supervised model verification ensemble by quantifying model diversity, aiming to boost the robustness of the target model against adversarial examples. Evaluated using eleven representative attacks on popular benchmark datasets, we show that MODEF achieves remarkable defense success rates, compared with existing defense methods, and provides a superior capability of repairing adversarial inputs and making correct predictions with high accuracy in the presence of black-box attacks.