 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Compiler Based FPGA Accelerator for CNN Training
Paper and Code
Aug 15, 2019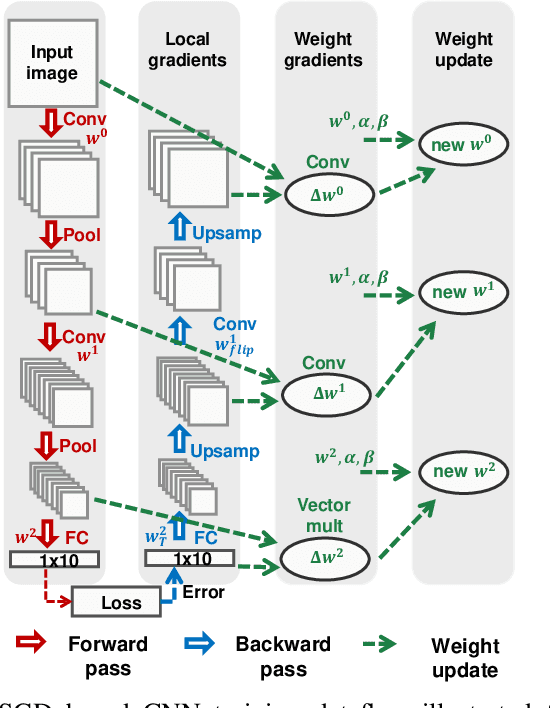
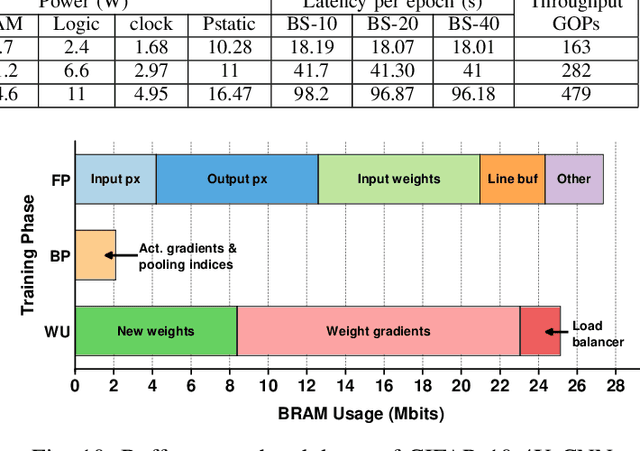
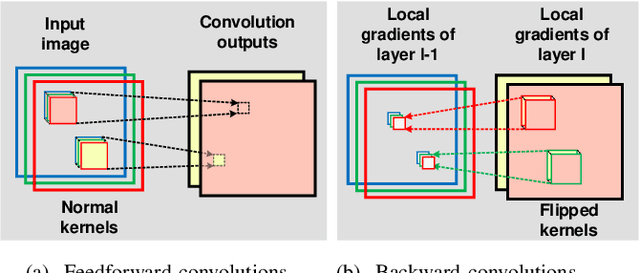
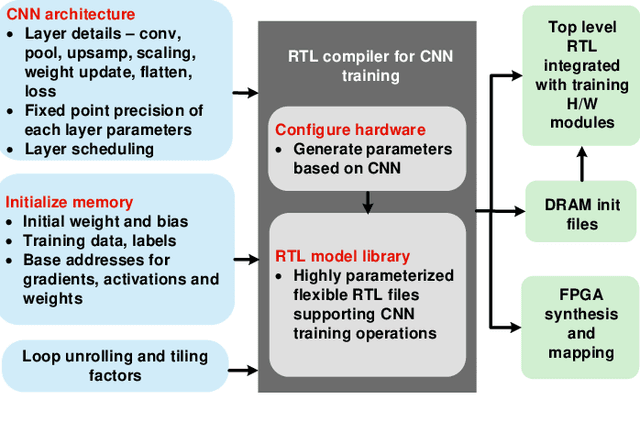
Training of convolutional neural networks (CNNs)on embedded platforms to support on-device learning is earning vital importance in recent days. Designing flexible training hard-ware is much more challenging than inference hardware, due to design complexity and large computation/memory requirement. In this work, we present an automatic compiler-based FPGA accelerator with 16-bit fixed-point precision for complete CNNtraining, including Forward Pass (FP), Backward Pass (BP) and Weight Update (WU). We implemented an optimized RTL library to perform training-specific tasks and developed an RTL compiler to automatically generate FPGA-synthesizable RTL based on user-defined constraints. We present a new cyclic weight storage/access scheme for on-chip BRAM and off-chip DRAMto efficiently implement non-transpose and transpose operations during FP and BP phases, respectively. Representative CNNs for CIFAR-10 dataset are implemented and trained on Intel Stratix 10-GX FPGA using proposed hardware architecture, demonstrating up to 479 GOPS performance.