 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Multi-Agent Temporal-Difference Learning via Homotopy Stochastic Primal-Dual Optimization
Paper and Code
Aug 24, 2019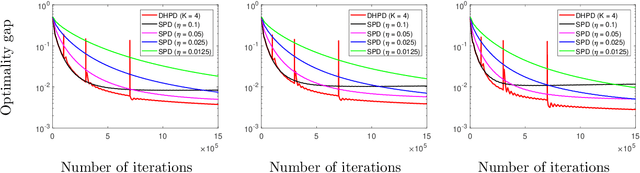
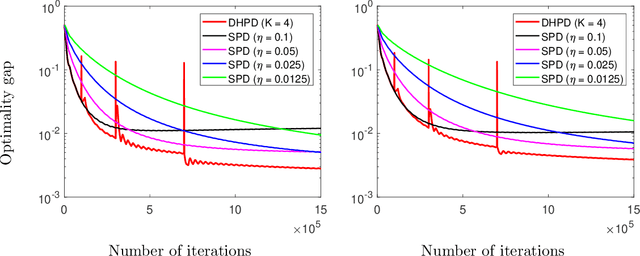
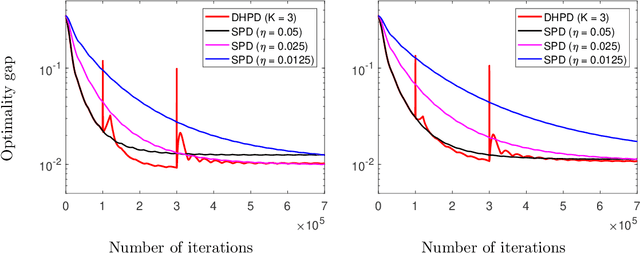
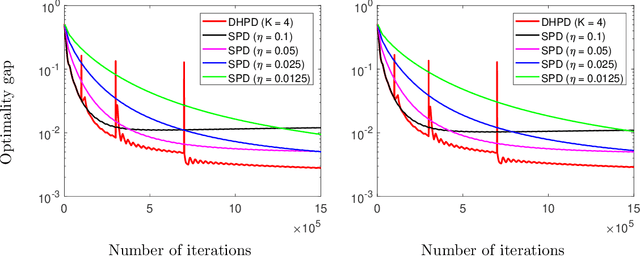
We consider a distributed multi-agent policy evaluation problem in reinforcement learning. In our setup, a group of agents with jointly observed states and private local actions and rewards collaborates to learn the value function of a given policy. When the dimension of state-action space is large, the temporal-difference learning with linear function approximation is widely used. Under the assumption that the samples are i.i.d., the best-known convergence rate for multi-agent temporal-difference learning is $O(1/\sqrt{T})$ minimizing the mean square projected Bellman error. In this paper, we formulate the temporal-difference learning as a distributed stochastic saddle point problem, and propose a new homotopy primal-dual algorithm by adaptively restarting the gradient update from the average of previous iterations. We prove that our algorithm enjoys an $O(1/T)$ convergence rate up to logarithmic factors of $T$, thereby significantly improving the previously-known convergence results on multi-agent temporal-difference learning. Furthermore, since our result explicitly takes into account the Markovian nature of the sampling in policy evaluation, it addresses a broader class of problems than the commonly used i.i.d. sampling scenario. From a stochastic optimization perspective, to the best of our knowledge, the proposed homotopy primal-dual algorithm is the first to achieve $O(1/T)$ convergence rate for distributed stochastic saddle point problem.