 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning with Multiple Ranked Experts
Paper and Code
Jul 31, 2019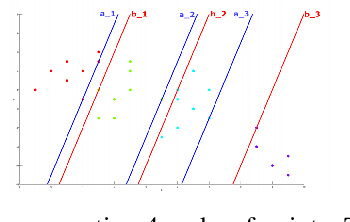
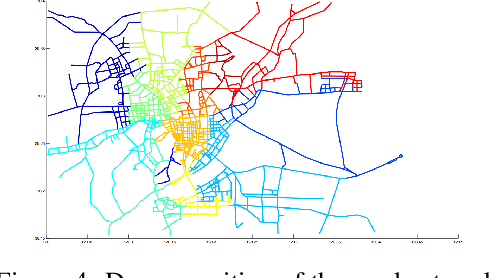
We consider the problem of learning to behave optimally in a Markov Decision Process when a reward function is not specified, but instead we have access to a set of demonstrators of varying performance. We assume the demonstrators are classified into one of k ranks, and use ideas from ordinal regression to find a reward function that maximizes the margin between the different ranks. This approach is based on the idea that agents should not only learn how to behave from experts, but also how not to behave from non-experts. We show there are MDPs where important differences in the reward function would be hidden from existing algorithms by the behaviour of the expert. Our method is particularly useful for problems where we have access to a large set of agent behaviours with varying degrees of expertise (such as through GPS or cellphones). We highlight the differences between our approach and existing methods using a simple grid domain and demonstrate its efficacy on determining passenger-finding strategies for taxi drivers, using a large dataset of GPS trajectories.