 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Grid Net: hand mesh vertex regression from single depth maps
Paper and Code
Jul 24, 2019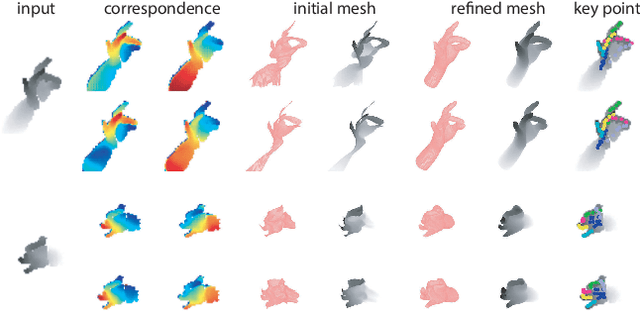
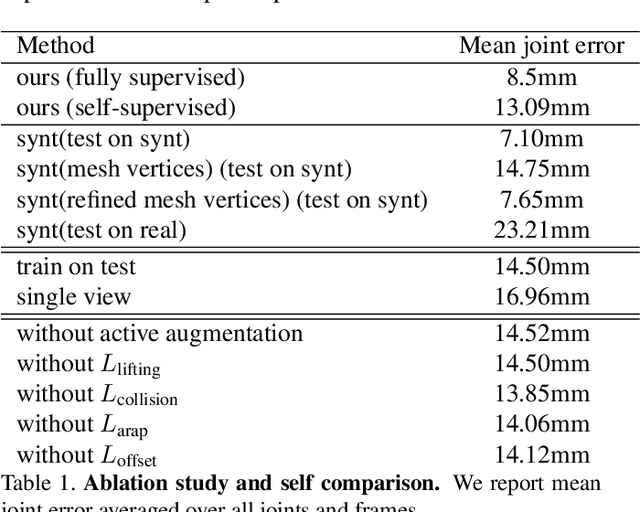
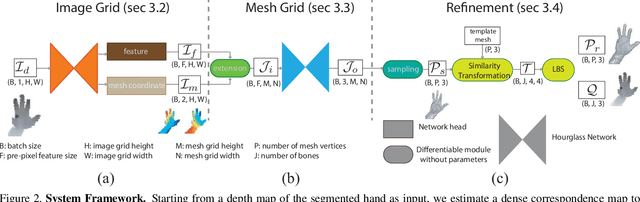

We present a method for recovering the dense 3D surface of the hand by regressing the vertex coordinates of a mesh model from a single depth map. To this end, we use a two-stage 2D fully convolutional network architecture. In the first stage, the network estimates a dense correspondence field for every pixel on the depth map or image grid to the mesh grid. In the second stage, we design a differentiable operator to map features learned from the previous stage and regress a 3D coordinate map on the mesh grid. Finally, we sample from the mesh grid to recover the mesh vertices, and fit it an articulated template mesh in closed form. During inference, the network can predict all the mesh vertices, transformation matrices for every joint and the joint coordinates in a single forward pass. When given supervision on the sparse key-point coordinates, our method achieves state-of-the-art accuracy on NYU dataset for key point localization while recovering mesh vertices and a dense correspondence map. Our framework can also be learned through self-supervision by minimizing a set of data fitting and kinematic prior terms. With multi-camera rig during training to resolve self-occlusion, it can perform competitively with strongly supervised methods Without any human annotation.