 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanBERT: Improving Pre-training by Representing and Predicting Spans
Paper and Code
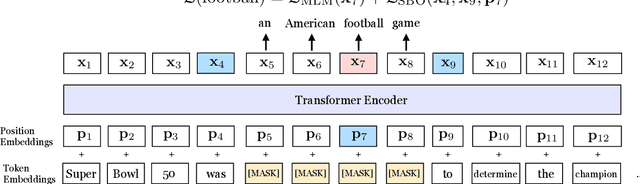
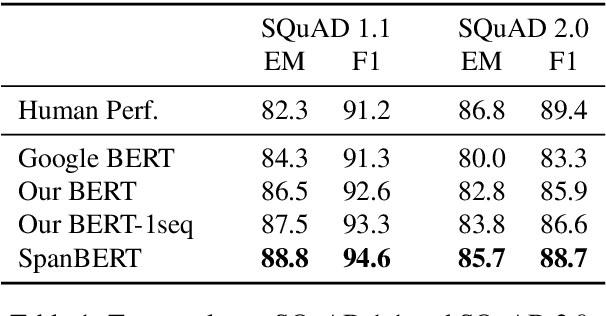
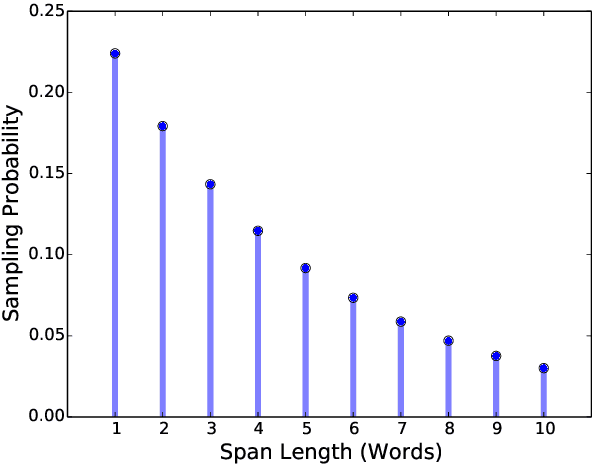
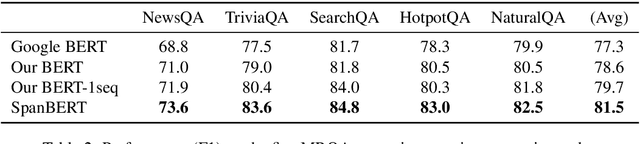
We present SpanBERT, a pre-training method that is designed to better represent and predict spans of text. Our approach extends BERT by (1) masking contiguous random spans, rather than random tokens, and (2) training the span boundary representations to predict the entire content of the masked span, without relying on the individual token representations within it. SpanBERT consistently outperforms BERT and our better-tuned baselines, with substantial gains on span selection tasks such as question answering and coreference resolution. In particular, with the same training data and model size as BERT-large, our single model obtains 94.6% and 88.7% F1 on SQuAD 1.1 and 2.0, respectively. We also achieve a new state of the art on the OntoNotes coreference resolution task (79.6\% F1), strong performance on the TACRED relation extraction benchmark, and even show gains on GLUE.