 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Inter-Layer Weight Prediction and Quantization for Deep Neural Networks based on a Smoothly Varying Weight Hypothesis
Paper and Code
Jul 16, 2019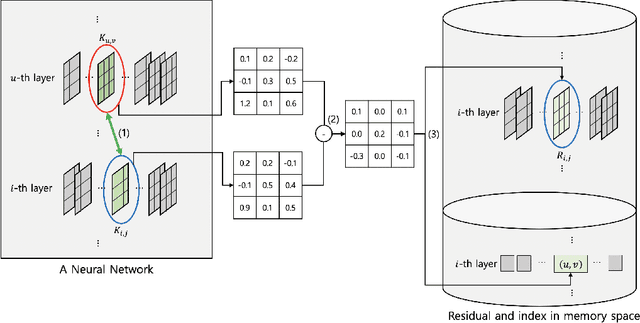
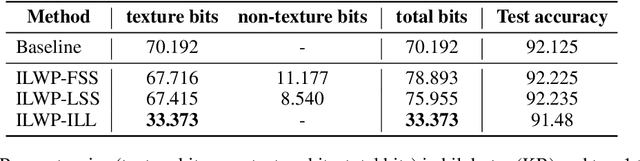
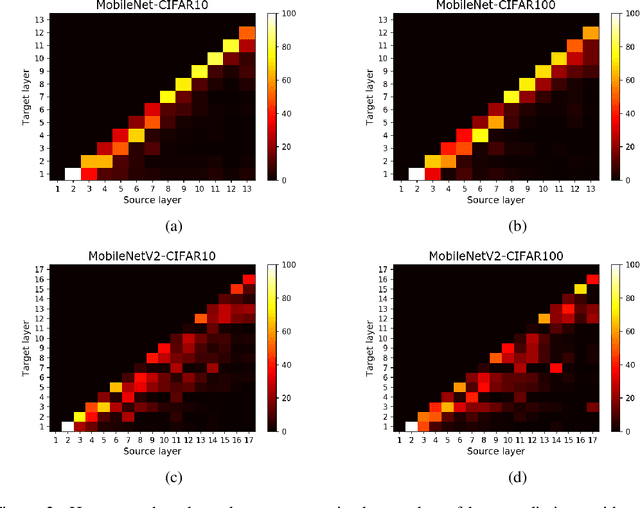
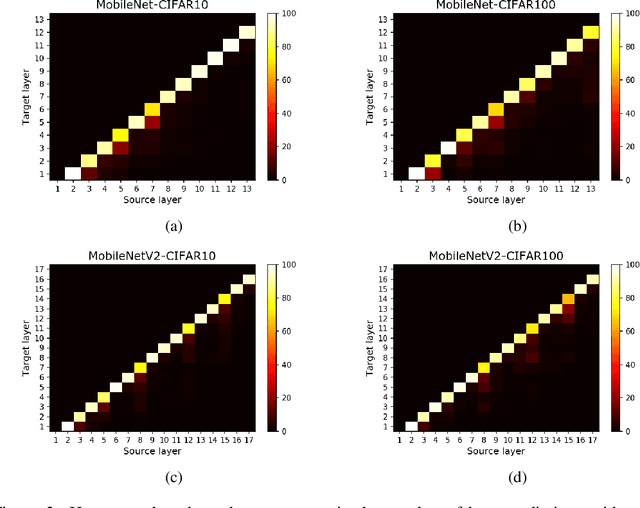
Network compression for deep neural networks has become an important part of deep learning research, because of increased demand for deep learning models in practical resource-constrained environments. In this paper, we observe that the weights in adjacent convolution layers share strong similarity in shapes and values, i.e., the weights tend to vary smoothly along the layers. We call this phenomenon \textit{Smoothly Varying Weight Hypothesis} (SVWH). Based on SVWH and an inter-frame prediction method in conventional video coding schemes, we propose a new \textit{Inter-Layer Weight Prediction} (ILWP) and quantization method which quantize the predicted residuals of the weights. Since the predicted weight residuals tend to follow Laplacian distributions with very low variance, the weight quantization can more effectively be applied, thus producing more zero weights and enhancing weight compression ratio. In addition, we propose a new loss for eliminating non-texture bits, which enabled us to more effectively store only texture bits. That is, the proposed loss regularizes the weights such that the collocated weights between the adjacent two layers have the same values. Our comprehensive experiments show that the proposed method achieved much higher weight compression rate at the same accuracy level compared with the previous quantization-based compression methods in deep neural networks.