 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Geometric Constraints in Monocular Video: Connecting Flow, Depth, and Camera
Paper and Code
Jul 12, 2019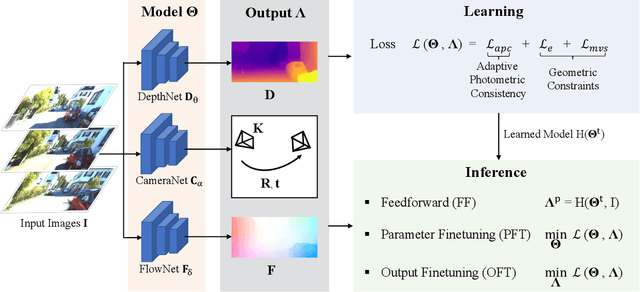
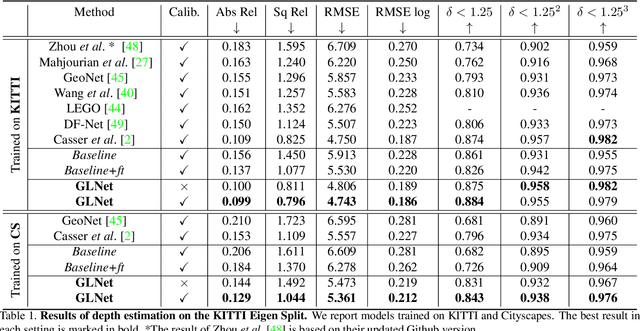
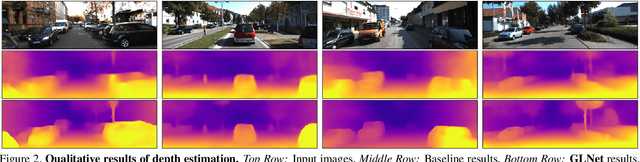

We present GLNet, a self-supervised framework for learning depth, optical flow, camera pose and intrinsic parameters from monocular video -- addressing the difficulty of acquiring realistic ground-truth for such tasks. We propose three contributions: 1) we design new loss functions that capture multiple geometric constraints (eg. epipolar geometry) as well as adaptive photometric costs that support multiple moving objects, rigid and non-rigid, 2) we extend the model such that it predicts camera intrinsics, making it applicable to uncalibrated video, and 3) we propose several online finetuning strategies that rely on the symmetry of our self-supervised loss in both training and testing, in particular optimizing model parameters and/or the output of different tasks, leveraging their mutual interactions. The idea of jointly optimizing the system output, under all geometric and photometric constraints can be viewed as a dense generalization of classical bundle adjustment. We demonstrate the effectiveness of our method on KITTI and Cityscapes, where we outperform previous self-supervised approaches on multiple tasks. We also show good generalization for transfer learning.