 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking AI Forget You: Data Deletion in Machine Learning
Paper and Code
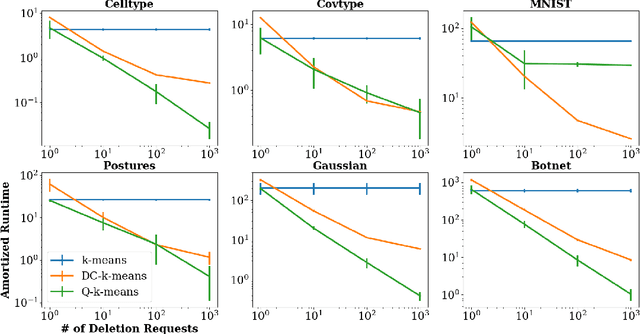
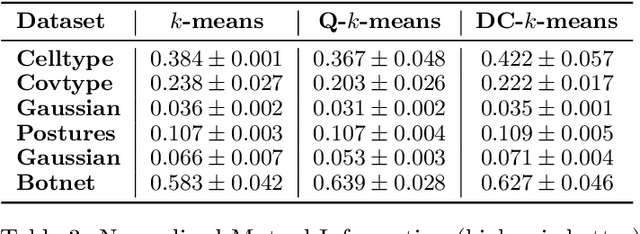
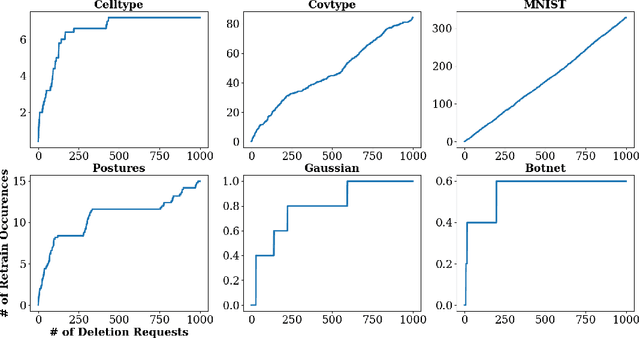
Intense recent discussions have focused on how to provide individuals with control over when their data can and cannot be used -- the EU's Right To Be Forgotten regulation is an example of this effort. In this paper we initiate a framework studying what to do when it is no longer permissible to deploy models derivative from specific user data. In particular, we formulate the problem of how to efficiently delete individual data points from trained machine learning models. For many standard ML models, the only way to completely remove an individual's data is to retrain the whole model from scratch on the remaining data, which is often not computationally practical. We investigate algorithmic principles that enable efficient data deletion in ML. For the specific setting of k-means clustering, we propose two provably deletion efficient algorithms which achieve an average of over 100X improvement in deletion efficiency across 6 datasets, while producing clusters of comparable statistical quality to a canonical k-means++ baseline.