 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Transparency of Machine Learning Systems through Analysis of Contributions
Paper and Code
Jul 08, 2019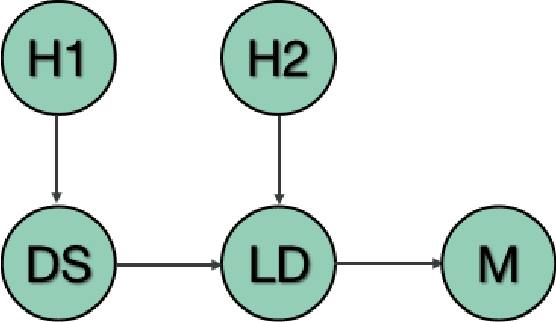

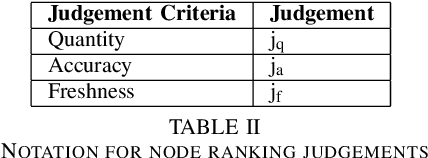
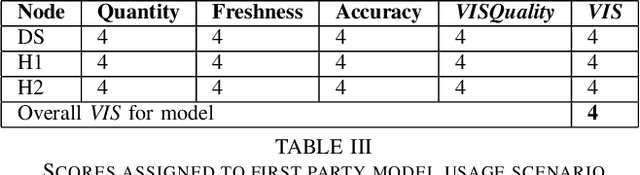
Increased adoption and deployment of machine learning (ML) models into business, healthcare and other organisational processes, will result in a growing disconnect between the engineers and researchers who developed the models and the model's users and other stakeholders, such as regulators or auditors. This disconnect is inevitable, as models begin to be used over a number of years or are shared among third parties through user communities or via commercial marketplaces, and it will become increasingly difficult for users to maintain ongoing insight into the suitability of the parties who created the model, or the data that was used to train it. This could become problematic, particularly where regulations change and once-acceptable standards become outdated, or where data sources are discredited, perhaps judged to be biased or corrupted, either deliberately or unwittingly. In this paper we present a method for arriving at a quantifiable metric capable of ranking the transparency of the process pipelines used to generate ML models and other data assets, such that users, auditors and other stakeholders can gain confidence that they will be able to validate and trust the data sources and human contributors in the systems that they rely on for their business operations. The methodology for calculating the transparency metric, and the type of criteria that could be used to make judgements on the visibility of contributions to systems are explained and illustrated through an example scenario.