 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Encoding for Byzantine-Resilient Distributed Optimization
Paper and Code
Jul 05, 2019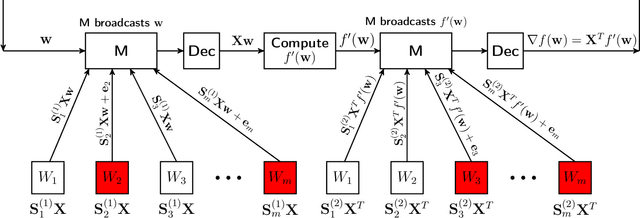
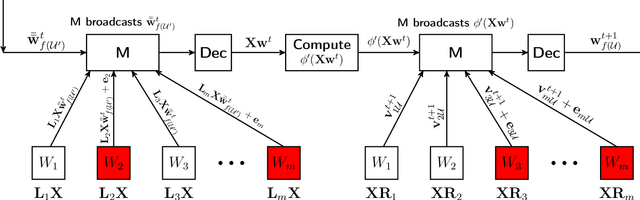
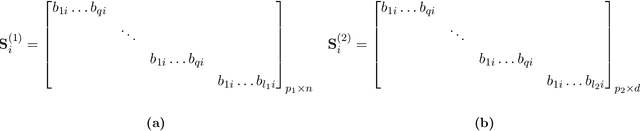
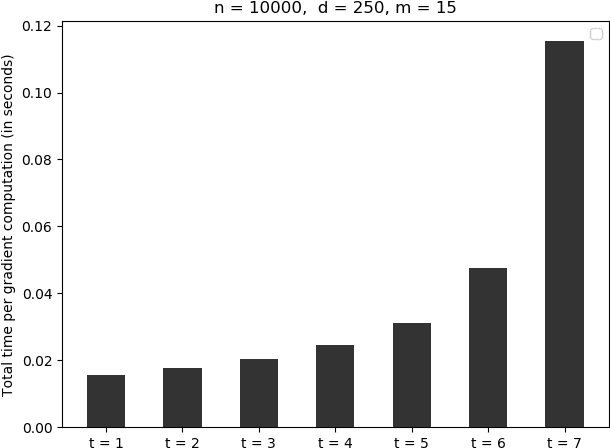
We study distributed optimization in the presence of Byzantine adversaries, where both data and computation are distributed among $m$ worker machines, $t$ of which can be corrupt and collaboratively deviate arbitrarily from their pre-specified programs, and a designated (master) node iteratively computes the model/parameter vector for {\em generalized linear models}. In this work, we primarily focus on two iterative algorithms: {\em Proximal Gradient Descent} (PGD) and {\em Coordinate Descent} (CD). Gradient descent (GD) is a special case of these algorithms. PGD is typically used in the data-parallel setting, where data is partitioned across different samples, whereas, CD is used in the model-parallelism setting, where the data is partitioned across the parameter space. In this paper, we propose a method based on data encoding and error correction over real numbers to combat adversarial attacks. We can tolerate up to $t\leq \lfloor\frac{m-1}{2}\rfloor$ corrupt worker nodes, which is information-theoretically optimal. We give deterministic guarantees, and our method does not assume any probability distribution on the data. We develop a {\em sparse} encoding scheme which enables computationally efficient data encoding and decoding. We demonstrate a trade-off between corruption threshold and the resource requirement (storage and computational/communication complexity). As an example, for $t\leq\frac{m}{3}$, our scheme incurs only a {\em constant} overhead on these resources, over that required by the plain distributed PGD/CD algorithms which provide no adversarial protection. Our encoding scheme extends {\em efficiently} to (i) the data streaming model, where data samples come in an online fashion and are encoded as they arrive, and (ii) making {\em stochastic gradient descent} (SGD) Byzantine-resilient. In the end, we give experimental results to show the efficacy of our method.