 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Uncertainty Reduction for Intention Recognition in Human-Robot Interaction
Paper and Code
Jul 04, 2019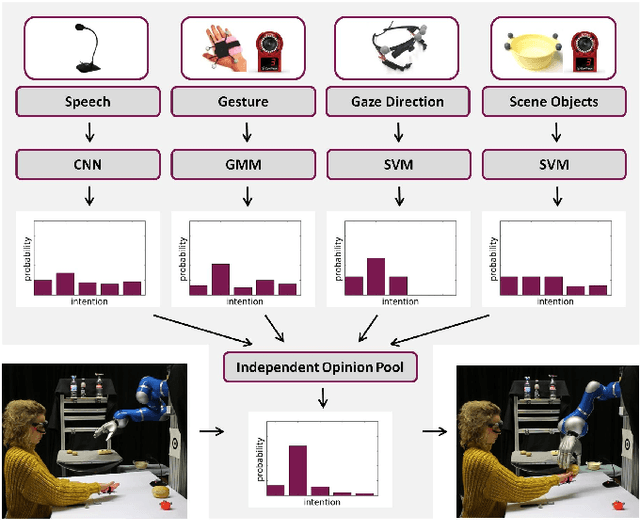
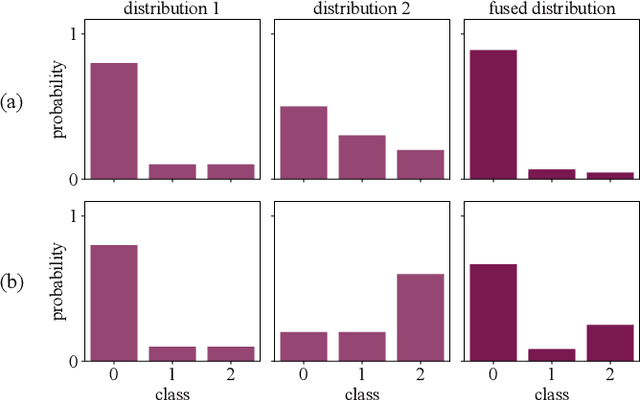

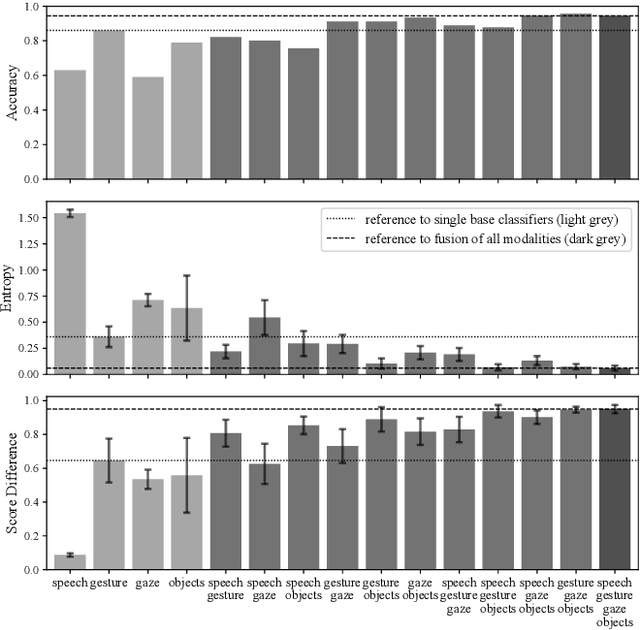
Assistive robots can potentially improve the quality of life and personal independence of elderly people by supporting everyday life activities. To guarantee a safe and intuitive interaction between human and robot, human intentions need to be recognized automatically. As humans communicate their intentions multimodally, the use of multiple modalities for intention recognition may not just increase the robustness against failure of individual modalities but especially reduce the uncertainty about the intention to be predicted. This is desirable as particularly in direct interaction between robots and potentially vulnerable humans a minimal uncertainty about the situation as well as knowledge about this actual uncertainty is necessary. Thus, in contrast to existing methods, in this work a new approach for multimodal intention recognition is introduced that focuses on uncertainty reduction through classifier fusion. For the four considered modalities speech, gestures, gaze directions and scene objects individual intention classifiers are trained, all of which output a probability distribution over all possible intentions. By combining these output distributions using the Bayesian method Independent Opinion Pool the uncertainty about the intention to be recognized can be decreased. The approach is evaluated in a collaborative human-robot interaction task with a 7-DoF robot arm. The results show that fused classifiers which combine multiple modalities outperform the respective individual base classifiers with respect to increased accuracy, robustness, and reduced uncertainty.