 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing from a few environments in safety-critical reinforcement learning
Paper and Code



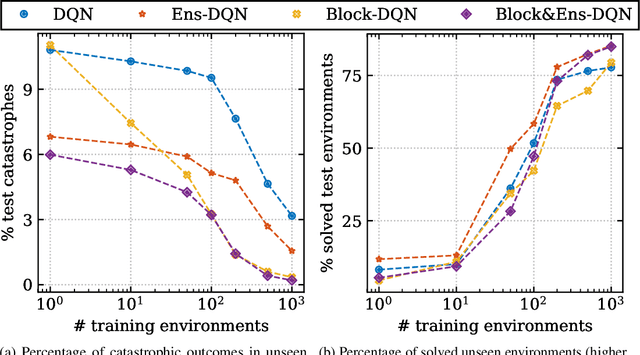
Before deploying autonomous agents in the real world, we need to be confident they will perform safely in novel situations. Ideally, we would expose agents to a very wide range of situations during training, allowing them to learn about every possible danger, but this is often impractical. This paper investigates safety and generalization from a limited number of training environments in deep reinforcement learning (RL). We find RL algorithms can fail dangerously on unseen test environments even when performing perfectly on training environments. Firstly, in a gridworld setting, we show that catastrophes can be significantly reduced with simple modifications, including ensemble model averaging and the use of a blocking classifier. In the more challenging CoinRun environment we find similar methods do not significantly reduce catastrophes. However, we do find that the uncertainty information from the ensemble is useful for predicting whether a catastrophe will occur within a few steps and hence whether human intervention should be requested.