 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Performance of End-to-End ASR on Numeric Sequences
Paper and Code
Jul 01, 2019
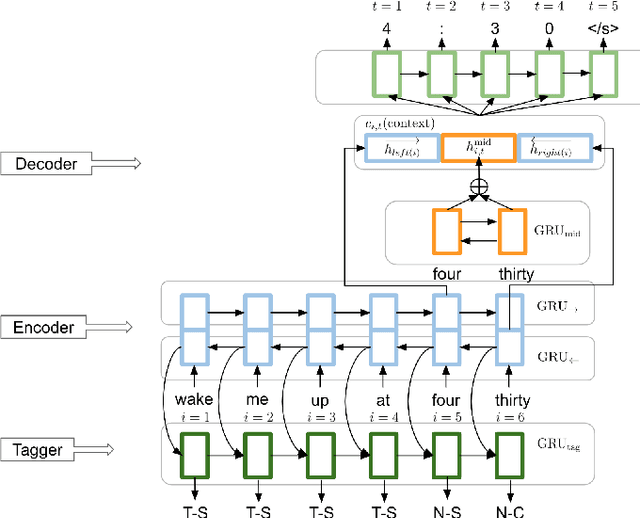
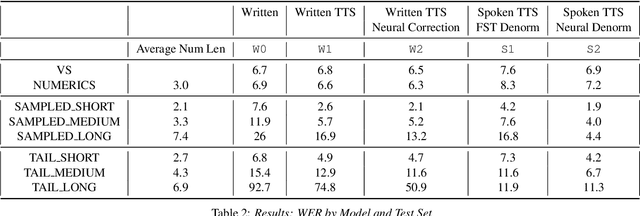
Recognizing written domain numeric utterances (e.g. I need $1.25.) can be challenging for ASR systems, particularly when numeric sequences are not seen during training. This out-of-vocabulary (OOV) issue is addressed in conventional ASR systems by training part of the model on spoken domain utterances (e.g. I need one dollar and twenty five cents.), for which numeric sequences are composed of in-vocabulary numbers, and then using an FST verbalizer to denormalize the result. Unfortunately, conventional ASR models are not suitable for the low memory setting of on-device speech recognition. E2E models such as RNN-T are attractive for on-device ASR, as they fold the AM, PM and LM of a conventional model into one neural network. However, in the on-device setting the large memory footprint of an FST denormer makes spoken domain training more difficult. In this paper, we investigate techniques to improve E2E model performance on numeric data. We find that using a text-to-speech system to generate additional numeric training data, as well as using a small-footprint neural network to perform spoken-to-written domain denorming, yields improvement in several numeric classes. In the case of the longest numeric sequences, we see reduction of WER by up to a factor of 8.