 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected Sarsa($λ$) with Control Variate for Variance Reduction
Paper and Code
Jun 25, 2019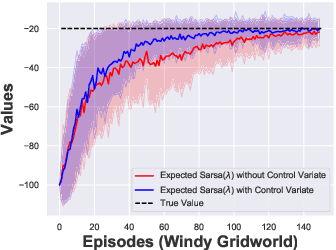

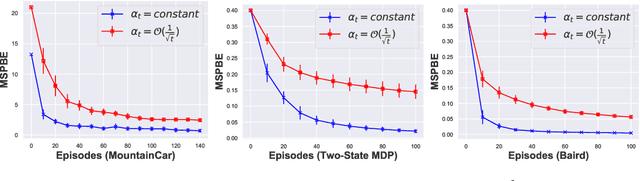
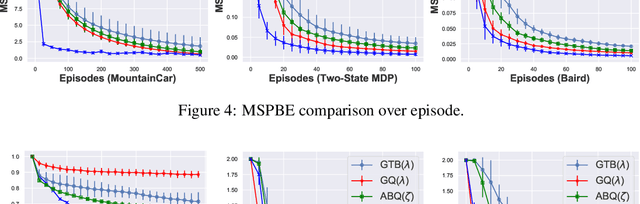
Off-policy learning is powerful for reinforcement learning. However, the high variance of off-policy evaluation is a critical challenge, which causes off-policy learning with function approximation falls into an uncontrolled instability. In this paper, for reducing the variance, we introduce control variate technique to Expected Sarsa($\lambda$) and propose a tabular ES($\lambda$)-CV algorithm. We prove that if a proper estimator of value function reaches, the proposed ES($\lambda$)-CV enjoys a lower variance than Expected Sarsa($\lambda$). Furthermore, to extend ES($\lambda$)-CV to be a convergent algorithm with linear function approximation, we propose the GES($\lambda$) algorithm under the convex-concave saddle-point formulation. We prove that the convergence rate of GES($\lambda$) achieves $\mathcal{O}(1/T)$, which matches or outperforms several state-of-art gradient-based algorithms, but we use a more relaxed step-size. Numerical experiments show that the proposed algorithm is stable and converges faster with lower variance than several state-of-art gradient-based TD learning algorithms: GQ($\lambda$), GTB($\lambda$) and ABQ($\zeta$).