 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Neural Architecture Search Through A Posteriori Distribution Guided Sampling
Paper and Code
Jun 23, 2019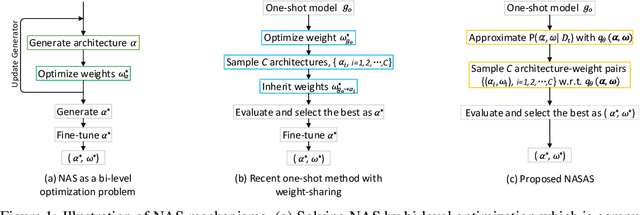
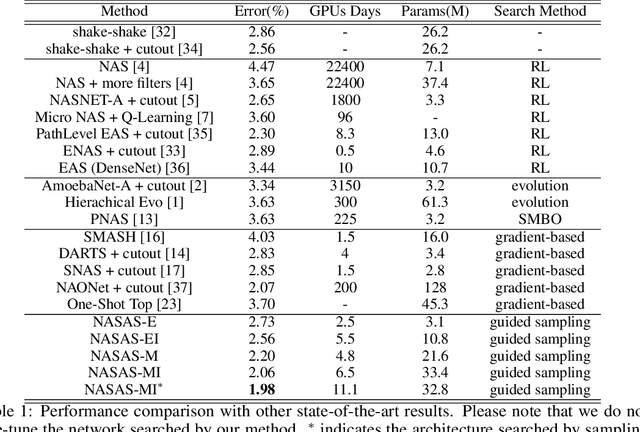
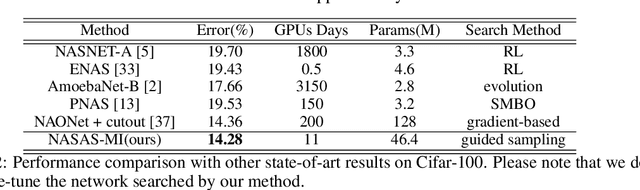
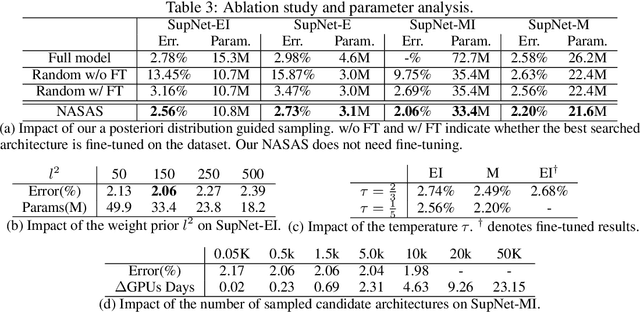
The emergence of one-shot approaches has greatly advanced the research on neural architecture search (NAS). Recent approaches train an over-parameterized super-network (one-shot model) and then sample and evaluate a number of sub-networks, which inherit weights from the one-shot model. The overall searching cost is significantly reduced as training is avoided for sub-networks. However, the network sampling process is casually treated and the inherited weights from an independently trained super-network perform sub-optimally for sub-networks. In this paper, we propose a novel one-shot NAS scheme to address the above issues. The key innovation is to explicitly estimate the joint a posteriori distribution over network architecture and weights, and sample networks for evaluation according to it. This brings two benefits. First, network sampling under the guidance of a posteriori probability is more efficient than conventional random or uniform sampling. Second, the network architecture and its weights are sampled as a pair to alleviate the sub-optimal weights problem. Note that estimating the joint a posteriori distribution is not a trivial problem. By adopting variational methods and introducing a hybrid network representation, we convert the distribution approximation problem into an end-to-end neural network training problem which is neatly approached by variational dropout. As a result, the proposed method reduces the number of sampled sub-networks by orders of magnitude. We validate our method on the fundamental image classification task. Results on Cifar-10, Cifar-100 and ImageNet show that our method strikes the best trade-off between precision and speed among NAS methods. On Cifar-10, we speed up the searching process by 20x and achieve a higher precision than the best network found by existing NAS methods.