 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multiplicative Noise in Stochastic Gradient Descent: Data-Dependent Regularization, Continuous and Discrete Approximation
Paper and Code
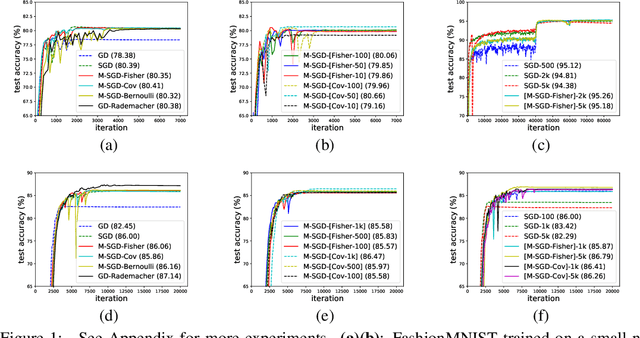
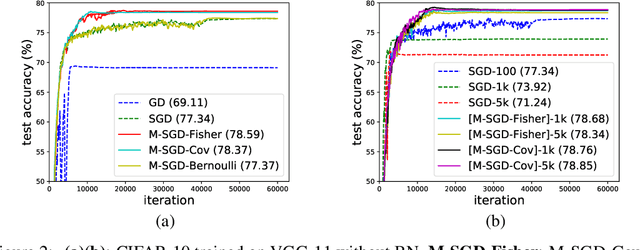
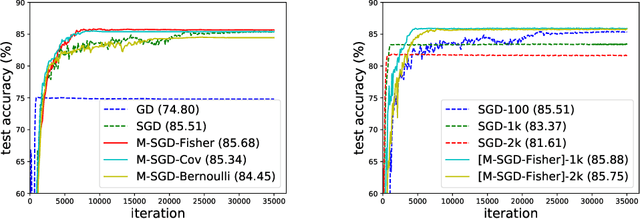
The randomness in Stochastic Gradient Descent (SGD) is considered to play a central role in the observed strong generalization capability of deep learning. In this work, we re-interpret the stochastic gradient of vanilla SGD as a matrix-vector product of the matrix of gradients and a random noise vector (namely multiplicative noise, M-Noise). Comparing to the existing theory that explains SGD using additive noise, the M-Noise helps establish a general case of SGD, namely Multiplicative SGD (M-SGD). The advantage of M-SGD is that it decouples noise from parameters, providing clear insights at the inherent randomness in SGD. Our analysis shows that 1) the M-SGD family, including the vanilla SGD, can be viewed as an minimizer with a data-dependent regularizer resemble of Rademacher complexity, which contributes to the implicit bias of M-SGD; 2) M-SGD holds a strong convergence to a continuous stochastic differential equation under the Gaussian noise assumption, ensuring the path-wise closeness of the discrete and continuous dynamics. For applications, based on M-SGD we design a fast algorithm to inject noise of different types (e.g., Gaussian and Bernoulli) into gradient descent. Based on the algorithm, we further demonstrate that M-SGD can approximate SGD with various noise types and recover the generalization performance, which reveals the potential of M-SGD to solve practical deep learning problems, e.g., large batch training with strong generalization performance. We have validated our observations on multiple practical deep learning scenarios.