 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning Strategies for Hindi-English Codemixed Sentiment Analysis
Paper and Code
Jun 18, 2019
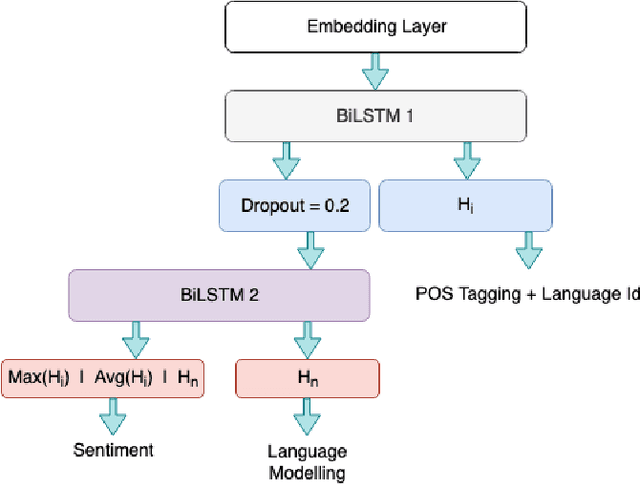


Sentiment Analysis and other semantic tasks are commonly used for social media textual analysis to gauge public opinion and make sense from the noise on social media. The language used on social media not only commonly diverges from the formal language, but is compounded by codemixing between languages, especially in large multilingual societies like India. Traditional methods for learning semantic NLP tasks have long relied on end to end task specific training, requiring expensive data creation process, even more so for deep learning methods. This challenge is even more severe for resource scarce texts like codemixed language pairs, with lack of well learnt representations as model priors, and task specific datasets can be few and small in quantities to efficiently exploit recent deep learning approaches. To address above challenges, we introduce curriculum learning strategies for semantic tasks in code-mixed Hindi-English (Hi-En) texts, and investigate various training strategies for enhancing model performance. Our method outperforms the state of the art methods for Hi-En codemixed sentiment analysis by 3.31% accuracy, and also shows better model robustness in terms of convergence, and variance in test performance.