 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable-Based Neural Units: Fully Quantizing Networks for Multiply-Free Inference
Paper and Code
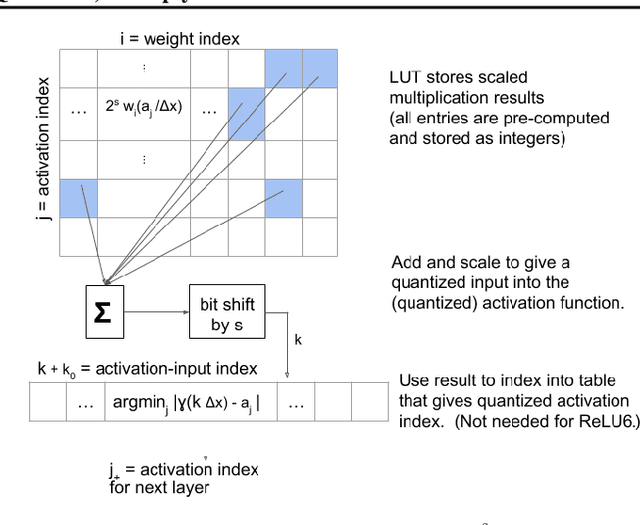
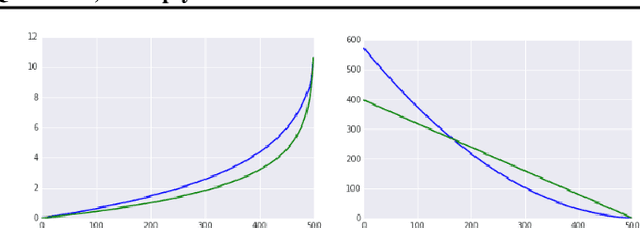
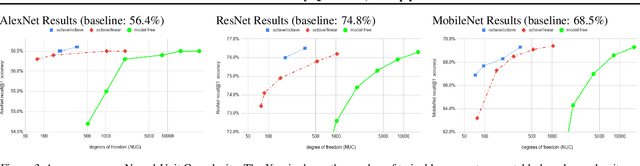
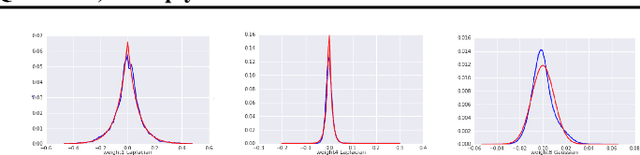
In this work, we propose to quantize all parts of standard classification networks and replace the activation-weight--multiply step with a simple table-based lookup. This approach results in networks that are free of floating-point operations and free of multiplications, suitable for direct FPGA and ASIC implementations. It also provides us with two simple measures of per-layer and network-wide compactness as well as insight into the distribution characteristics of activationoutput and weight values. We run controlled studies across different quantization schemes, both fixed and adaptive and, within the set of adaptive approaches, both parametric and model-free. We implement our approach to quantization with minimal, localized changes to the training process, allowing us to benefit from advances in training continuous-valued network architectures. We apply our approach successfully to AlexNet, ResNet, and MobileNet. We show results that are within 1.6% of the reported, non-quantized performance on MobileNet using only 40 entries in our table. This performance gap narrows to zero when we allow tables with 320 entries. Our results give the best accuracies among multiply-free networks.