 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimic and Fool: A Task Agnostic Adversarial Attack
Paper and Code

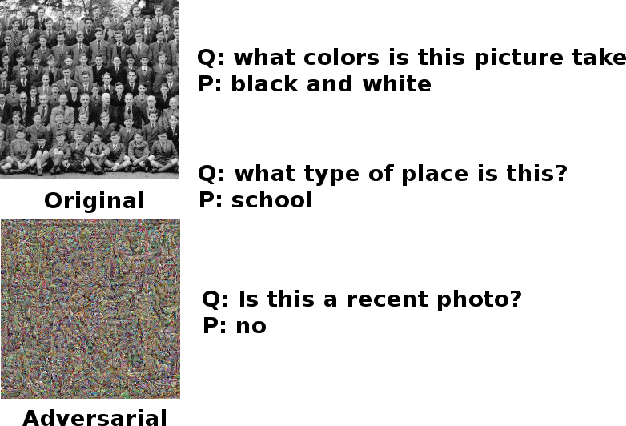


At present, adversarial attacks are designed in a task-specific fashion. However, for downstream computer vision tasks such as image captioning, image segmentation etc., the current deep learning systems use an image classifier like VGG16, ResNet50, Inception-v3 etc. as a feature extractor. Keeping this in mind, we propose Mimic and Fool, a task agnostic adversarial attack. Given a feature extractor, the proposed attack finds an adversarial image which can mimic the image feature of the original image. This ensures that the two images give the same (or similar) output regardless of the task. We randomly select 1000 MSCOCO validation images for experimentation. We perform experiments on two image captioning models, Show and Tell, Show Attend and Tell and one VQA model, namely, end-to-end neural module network (N2NMN). The proposed attack achieves success rate of 74.0%, 81.0% and 89.6% for Show and Tell, Show Attend and Tell and N2NMN respectively. We also propose a slight modification to our attack to generate natural-looking adversarial images. In addition, it is shown that the proposed attack also works for invertible architecture. Since Mimic and Fool only requires information about the feature extractor of the model, it can be considered as a gray-box attack.