 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Scheduled Sampling
Paper and Code
Jun 11, 2019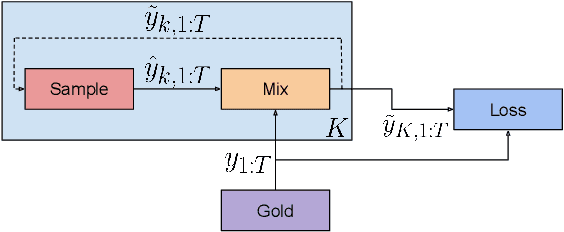
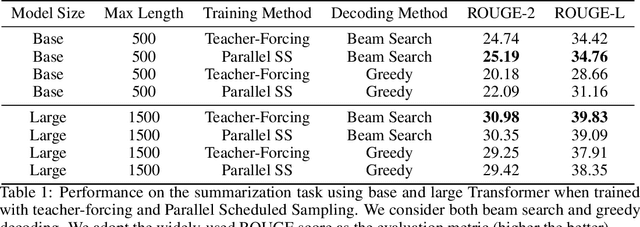
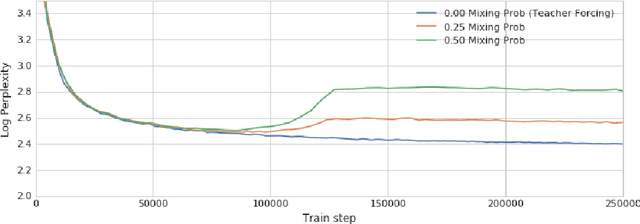
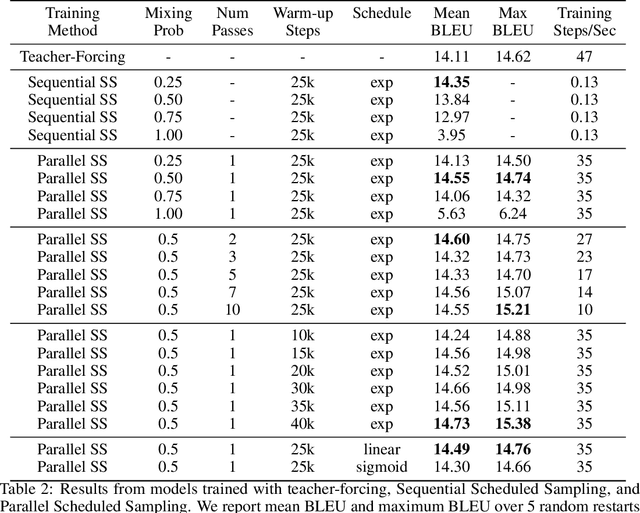
Auto-regressive models are widely used in sequence generation problems. The output sequence is typically generated in a predetermined order, one discrete unit (pixel or word or character) at a time. The models are trained by teacher-forcing where ground-truth history is fed to the model as input, which at test time is replaced by the model prediction. Scheduled Sampling aims to mitigate this discrepancy between train and test time by randomly replacing some discrete units in the history with the model's prediction. While teacher-forced training works well with ML accelerators as the computation can be parallelized across time, Scheduled Sampling involves undesirable sequential processing. In this paper, we introduce a simple technique to parallelize Scheduled Sampling across time. We find that in most cases our technique leads to better empirical performance on summarization and dialog generation tasks compared to teacher-forced training. Further, we discuss the effects of different hyper-parameters associated with Scheduled Sampling on the model performance.