 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift-of-Perspective Identification Within Legal Cases
Paper and Code
Jul 17, 2019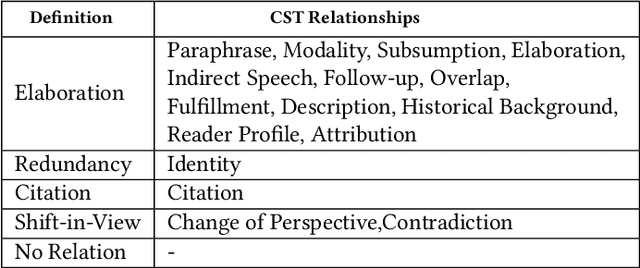
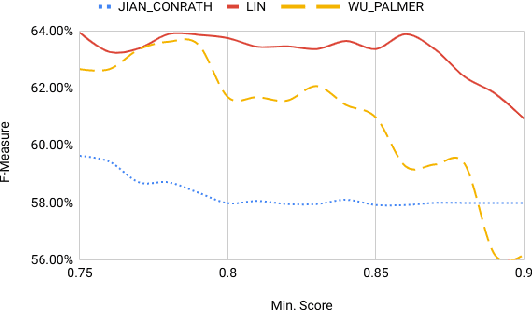
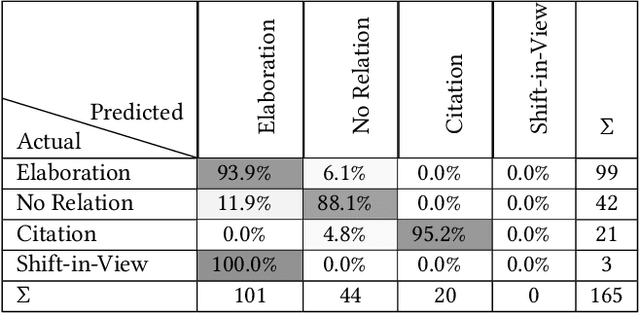
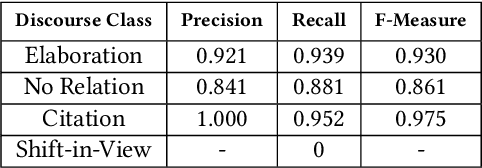
Arguments, counter-arguments, facts, and evidence obtained via documents related to previous court cases are of essential need for legal professionals. Therefore, the process of automatic information extraction from documents containing legal opinions related to court cases can be considered to be of significant importance. This study is focused on the identification of sentences in legal opinion texts which convey different perspectives on a certain topic or entity. We combined several approaches based on semantic analysis, open information extraction, and sentiment analysis to achieve our objective. Then, our methodology was evaluated with the help of human judges. The outcomes of the evaluation demonstrate that our system is successful in detecting situations where two sentences deliver different opinions on the same topic or entity. The proposed methodology can be used to facilitate other information extraction tasks related to the legal domain. One such task is the automated detection of counter arguments for a given argument. Another is the identification of opponent parties in a court case.