 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tunable Loss Function for Classification
Paper and Code
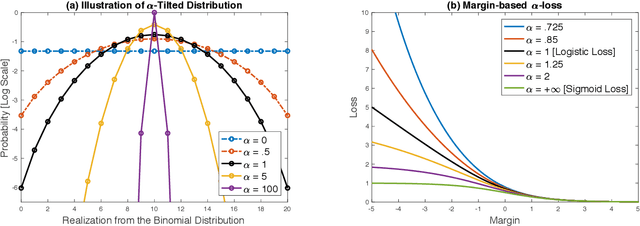

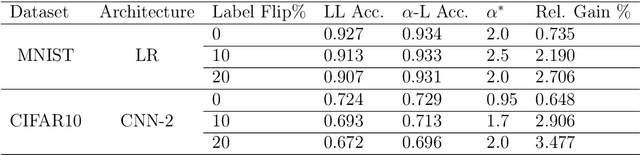
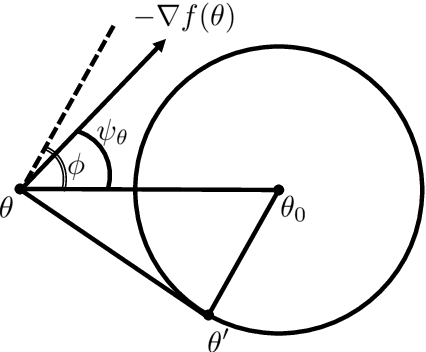
Recently, a parametrized class of loss functions called $\alpha$-loss, $\alpha \in [1,\infty]$, has been introduced for classification. This family, which includes the log-loss and the 0-1 loss as special cases, comes with compelling properties including an equivalent margin-based form which is classification-calibrated for all $\alpha$. We introduce a generalization of this family to the entire range of $\alpha \in (0,\infty]$ and establish how the parameter $\alpha$ enables the practitioner to choose among a host of operating conditions that are important in modern machine learning tasks. We prove that smaller $\alpha$ values are more conducive to faster optimization; in fact, $\alpha$-loss is convex for $\alpha \le 1$ and quasi-convex for $\alpha >1$. Moreover, we establish bounds to quantify the degradation of the local-quasi-convexity of the optimization landscape as $\alpha$ increases; we show that this directly translates to a computational slow down. On the other hand, our theoretical results also suggest that larger $\alpha$ values lead to better generalization performance. This is a consequence of the ability of the $\alpha$-loss to limit the effect of less likely data as $\alpha$ increases from 1, thereby facilitating robustness to outliers and noise in the training data. We provide strong evidence supporting this assertion with several experiments on benchmark datasets that establish the efficacy of $\alpha$-loss for $\alpha > 1$ in robustness to errors in the training data. Of equal interest is the fact that, for $\alpha < 1$, our experiments show that the decreased robustness seems to counteract class imbalances in training data.