 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlabeled Data Improves Adversarial Robustness
Paper and Code
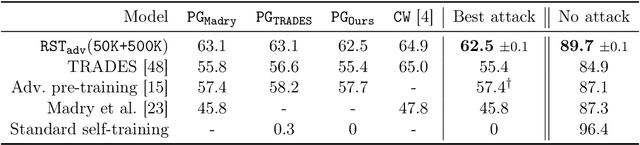
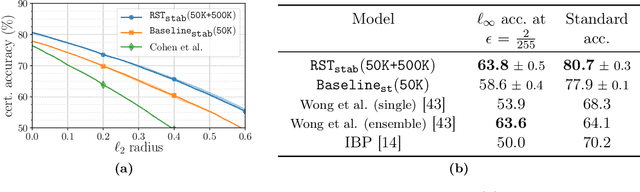


We demonstrate, theoretically and empirically, that adversarial robustness can significantly benefit from semisupervised learning. Theoretically, we revisit the simple Gaussian model of Schmidt et al. that shows a sample complexity gap between standard and robust classification. We prove that this gap does not pertain to labels: a simple semisupervised learning procedure (self-training) achieves robust accuracy using the same number of labels required for standard accuracy. Empirically, we augment CIFAR-10 with 500K unlabeled images sourced from 80 Million Tiny Images and use robust self-training to outperform state-of-the-art robust accuracies by over 5 points in (i) $\ell_\infty$ robustness against several strong attacks via adversarial training and (ii) certified $\ell_2$ and $\ell_\infty$ robustness via randomized smoothing. On SVHN, adding the dataset's own extra training set with the labels removed provides gains of 4 to 10 points, within 1 point of the gain from using the extra labels as well.