 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiaBLa: A Corpus of Bilingual Spontaneous Written Dialogues for Machine Translation
Paper and Code
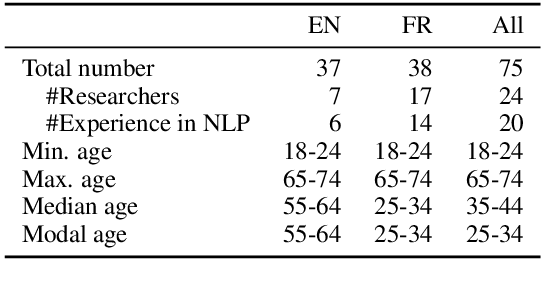
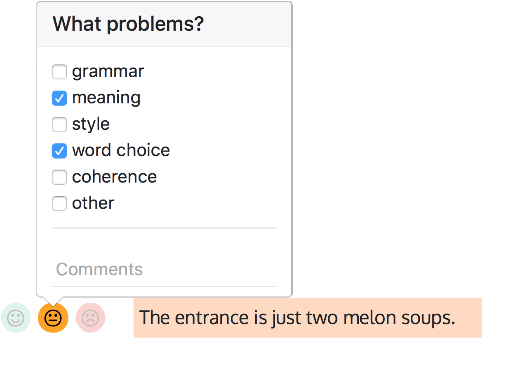
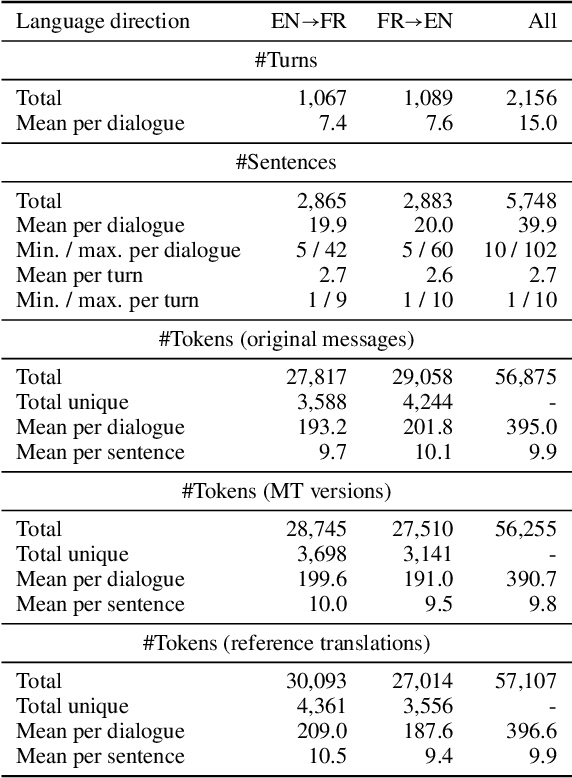

We present a new English-French test set for the evaluation of Machine Translation (MT) for informal, written bilingual dialogue. The test set contains 144 spontaneous dialogues (5,700+ sentences) between native English and French speakers, mediated by one of two neural MT systems in a range of role-play settings. The dialogues are accompanied by fine-grained sentence-level judgments of MT quality, produced by the dialogue participants themselves, as well as by manually normalised versions and reference translations produced a posteriori. The motivation for the corpus is two-fold: to provide (i) a unique resource for evaluating MT models, and (ii) a corpus for the analysis of MT-mediated communication. We provide a preliminary analysis of the corpus to confirm that the participants' judgments reveal perceptible differences in MT quality between the two MT systems used.