 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Clustering for Robust Unsupervised Domain Adaptation
Paper and Code
May 30, 2019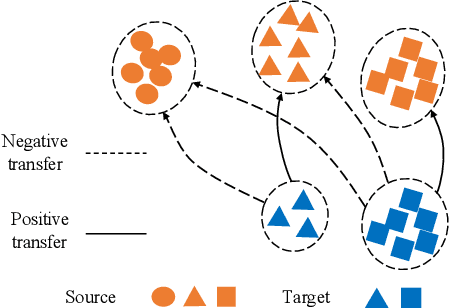
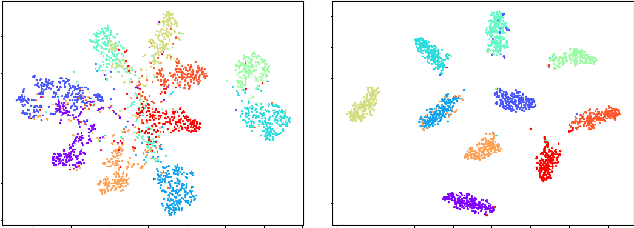
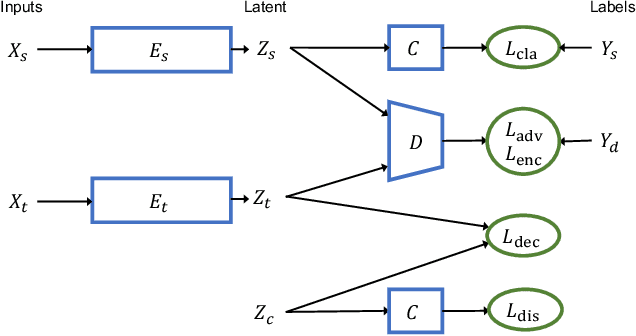
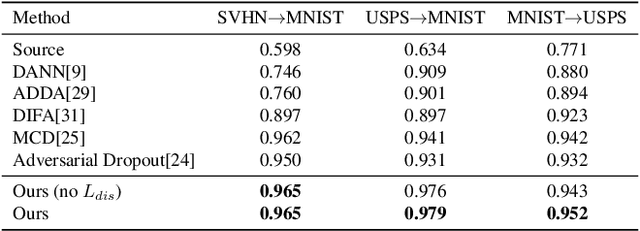
Unsupervised domain adaptation seeks to learn an invariant and discriminative representation for an unlabeled target domain by leveraging the information of a labeled source dataset. We propose to improve the discriminative ability of the target domain representation by simultaneously learning tightly clustered target representations while encouraging that each cluster is assigned to a unique and different class from the source. This strategy alleviates the effects of negative transfer when combined with adversarial domain matching between source and target representations. Our approach is robust to differences in the source and target label distributions and thus applicable to both balanced and imbalanced domain adaptation tasks, and with a simple extension, it can also be used for partial domain adaptation. Experiments on several benchmark datasets for domain adaptation demonstrate that our approach can achieve state-of-the-art performance in all three scenarios, namely, balanced, imbalanced and partial domain adaptation.