 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice-based lightly-supervised acoustic model training
Paper and Code
May 30, 2019
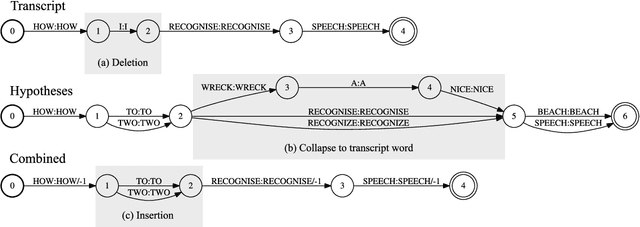
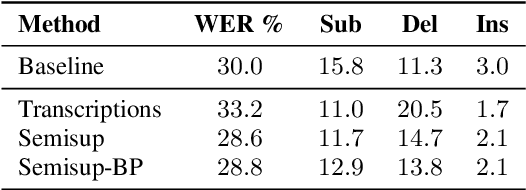
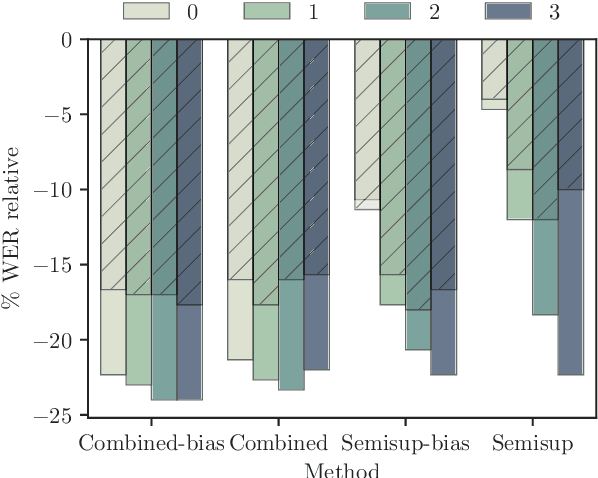
In the broadcast domain there is an abundance of related text data and partial transcriptions, such as closed captions and subtitles. This text data can be used for lightly supervised training, in which text matching the audio is selected using an existing speech recognition model. Current approaches to light supervision typically filter the data based on matching error rates between the transcriptions and biased decoding hypotheses. In contrast, semi-supervised training does not require matching text data, instead generating a hypothesis using a background language model. State-of-the-art semi-supervised training uses lattice-based supervision with the lattice-free MMI (LF-MMI) objective function. We propose a technique to combine inaccurate transcriptions with the lattices generated for semi-supervised training, thus preserving uncertainty in the lattice where appropriate. We demonstrate that this combined approach reduces the expected error rates over the lattices, and reduces the word error rate (WER) on a broadcast task.