 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Training Multi-Modal Networks Hard?
Paper and Code
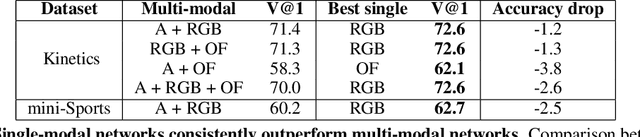
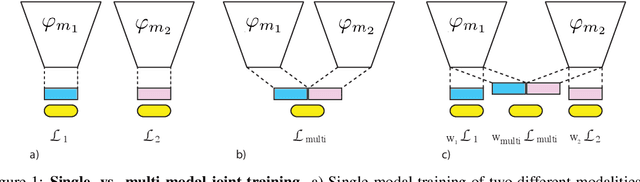
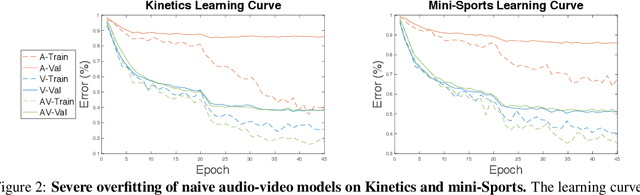

Consider end-to-end training of a multi-modal vs. a single-modal network on a task with multiple input modalities: the multi-modal network receives more information, so it should match or outperform its single-modal counterpart. In our experiments, however, we observe the opposite: the best single-modal network always outperforms the multi-modal network. This observation is consistent across different combinations of modalities and on different tasks and benchmarks. This paper identifies two main causes for this performance drop: first, multi-modal networks are often prone to overfitting due to increased capacity. Second, different modalities overfit and generalize at different rates, so training them jointly with a single optimization strategy is sub-optimal. We address these two problems with a technique we call Gradient Blending, which computes an optimal blend of modalities based on their overfitting behavior. We demonstrate that Gradient Blending outperforms widely-used baselines for avoiding overfitting and achieves state-of-the-art accuracy on various tasks including fine-grained sport classification, human action recognition, and acoustic event detection.